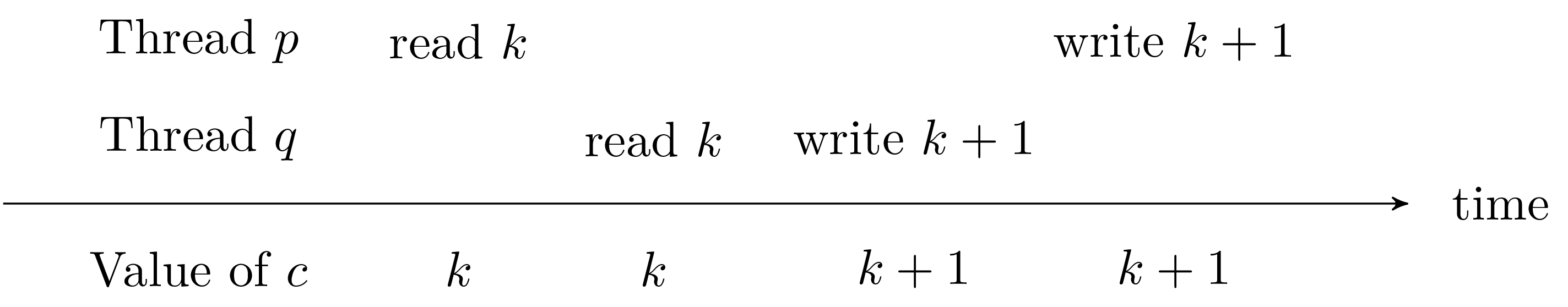A thread, also called a lightweight process, is a flow of control that can execute in parallel with other threads in the same program.
This chapter describes the functions that allow a program to create
threads (Thread module) and synchronize by means of locks
(Mutex module), conditions (Condition module), and
synchronous events (Event module).
The creation of a thread is very different from the fork operation that creates a copy of the current process (and therefore a copy of the program). After a fork, the address spaces of the parent and child are totally disjoint, and the two processes can communicate only through system calls (like reading or writing a file or a pipe).
In contrast, all the threads within a program share the same address space. The only information that is not shared, and differentiates one thread from another, is the thread’s identity and its execution stack (along with certain system information such as the signal mask, the state of locks and conditions, etc.) From this viewpoint, threads resemble coroutines. The threads within a given program are all treated in the same fashion, except for the initial thread that was created when the program started. When this thread terminates, so do all the other threads and therefore the program as a whole. (Whenever we speak of multiple threads, we will implicitly mean threads within a given program.)
But unlike coroutines, which pass control explicitly from one to another and cannot execute in parallel, threads can execute in parallel and can be scheduled preemptively by the system. From this viewpoint, threads resemble processes.
The common address space permits threads to communicate directly among themselves using shared memory. The fact that threads can execute in parallel means that they must synchronize their access to shared data, so that one finishes writing before the other begins reading. Although not necessary in principle, in practice this requires going through the operating system. Synchronization is often a difficult part of programming with threads. It can be done with locks and conditions, or in a higher-level fashion with events.
The advantages of threads over processes are the lower cost of creation and the ability to exchange large data structures simply by passing pointers rather than copying.
On the other hand, using threads incurs the cost of managing the synchronization among them, including the case of a fatal error in one of the threads. In particular, a thread must be careful to release its locks and preserve its invariant before stopping. Processes may also be preferable to threads when we cannot really benefit from the latter’s advantages.
To compile an application using native threads, use the following:
If the ocamlbuild tool is used, all that is needed is to add the
following to the _tags file:
If your installation does not support native threads, you can refer to section 7.8 or the manual for instructions how to use simulated “vm-level” threads. The text and examples in this chapter assume native threads and do not apply, in general, to vm-level threads.
The functions described in this section are defined in the
Thread module.
The system call create f v creates a new thread that
executes the function application f v and returns a thread id that
the caller can use to control the newly-created thread.
The function application executes concurrently with the other threads in the program. The thread terminates when the application returns and its result is simply ignored. If the thread terminates with an uncaught exception, the exception is not propagated to any other thread: a message is printed on the standard error output and the exception is otherwise ignored. (The other threads have proceeded independently and would not be able to receive the exception.)
A thread can also terminate prematurely with the system call
exit of the Thread module, not to be confused with
Pervasives.exit that terminates the
entire program, i.e. all its threads.
The initial thread of a program implicitly calls the
Pervasives.exit function when it terminates.
When another thread terminates before the initial thread, it is
deallocated immediately by the OCaml runtime library. It does not
become a zombie as in the case of a Unix process created by fork.
The system call self returns the thread id of the calling thread.
We already know enough to propose an alternative to the preceding
model for the concurrent server that used “fork” (or
“double fork”) — by using a thread rather than a child process.
To establish such a server, we introduce a variant
Misc.co_treatment of the function Misc.fork_treatment
defined in section 6.7.
If the thread was successfully created, the treatment is handled
entirely by the service function, including closing
client_descr. Otherwise, we close the client_descr
descriptor, the client is abandoned, and we let the main program
handle the error.
Note that all the difficulty of the co-server is hidden in the
service function, which must handle the connection robustly until
disconnection. In the case of a concurrent server where the service
is executed by another process, premature termination of the service
due to a fatal error produces by default the desired behavior — closing
the connection — because the system closes the file descriptors when a
process exits. But in the case where the service is executed by a
thread, the descriptors of the different threads are shared by default
and not closed at the termination of the thread. It is therefore up
to the thread to close its descriptors before exiting. In addition, a
thread cannot call Pervasives.exit in the case of a fatal error
during the handling of a service, because it would stop not only the
service but also the entire server. Calling Thread.exit is often
not a solution either, because we risk not having properly
deallocated the thread’s open resources, and in particular the
connection.
One solution consists of raising an exception to signify a fatal stop
(for example an Exit exception), causing finalization code to be
executed as it is handled. For similar reasons, it is essential to
block the sigpipe signal during the handling of a service by a
thread, replacing the immediate termination of the thread by the
raising of an EPIPE exception.
The functions described in this section are defined in the
Thread module.
The system call join allows one thread to wait for another to finish.
The calling thread is suspended until the thread with the given thread id has terminated its execution. This function can also be used by the principal thread to wait for all the other threads to finish before terminating itself and the program. (The default behavior is to kill the other threads without waiting for them to terminate.)
Although this call is blocking and therefore “long”, it
is restarted automatically when a signal is received: it is
effectively interrupted by the signal, the handler is invoked, then the
call is restarted. The call therefore does not return until the
thread has really terminated, and the call never raises the EINTR
exception. From the viewpoint of the OCaml programmer, it behaves as
if the signal was received at the moment when the call returns.
A thread does not return, since it is executed asynchronously. But its action can be observed — luckily! — by its side effects. For example, one thread can place the result of a computation in a reference that another thread will consult after making sure that the calculation has finished. We illustrate this in the following example.
The system can suspend one thread in order to give control temporarily
to another, or because it is waiting for a resource being used by
another thread (locks and conditions, for example) or by another
process (file descriptors, for example). A thread can also suspend
itself voluntarily. The yield function allows a thread to give
up control explicitly, without waiting for preemption by the system.
It is a hint for the thread scheduler, but it may have no effect, for example if no other thread can execute immediately, the system may give control back to the same thread.
Conversely, it is not necessary to execute yield to permit other
threads to execute, because the system reserves the right to execute
the yield command itself at any moment. In fact, it exercises
this right sufficiently often to permit other threads to execute and
to give the illusion that the threads are running in parallel, even on
a uniprocessor machine.
We can revisit the example of section 3.3 and modify it to use threads rather than processes.
The function psearch k f v searches with k threads in
parallel for an array element satisfying the function f.
The function pcond allows the search to be interrupted when an
answer has been found. All the threads share the same reference
found: they can therefore access it concurrently. No critical
section is required, because if different threads write to this resource
in parallel, they write the same value. It is important that the
threads do not write the result of the search when it is false!
For example, replacing line 7 by
or even:
would be incorrect.
The parallel search is interesting even on a uniprocessor machine if the comparison of elements could be blocked temporarily (for example by disk accesses or network connections). In this case, the thread performing the search passes control to another and the machine can therefore continue the computation on another part of the array and return to the blocked thread when its resource is free.
Access to certain elements can have significant latency, on the order
of a second if information must be retrieved over the network. In
this case, the difference in behavior between a sequential search and
a parallel search becomes obvious.
The other forms of suspension are tied to operating system resources.
A thread can be suspended for a certain time by calling delay s.
Once s seconds elapse, it can be restarted.
This primitive is provided for portability with vm-level threads, but
delay s is simply an abbreviation for
ignore (Unix.select [] [] [] s). This call, unlike join, is
not restarted when it is interrupted by a signal.
To synchronize a thread with an external operation, we can use the
select command. Note that this will block only the
calling thread and not the entire program. (The Thread module
redefines this function, because in the case of simulated threads
calling the one in the Unix module would block the whole program
and therefore all the threads. It is therefore necessary to use
select from the Thread module and not
Unix.select, even if the two are equivalent in the case of native
threads.)
To make the Sieve of Eratosthenes example of section 5.2
work with threads instead of by duplication of Unix processes,
it suffices to replace the
lines 5–16 of the
function filter by:
and the lines 4–10 of the function
sieve by:
However, we cannot expect any significant gain from this example, which uses few processes relative to computation time.
The functions in this section are defined in the
Mutex module (as in Mutual exclusion).
We mentioned above a problem of concurrent access to mutable resources. In particular, the following scenario illustrates the problem of access to shared resources. Consider a counter c and two processes p and q, each incrementing the counter in parallel.
Assume the scenario described in figure 6. Thread p reads the value of counter c, then gives control to q. In its turn, q reads the value of c, then writes the value k+1 to c. The thread p resumes control and writes the value k+1 to c. The final value of c is therefore k+1 instead of k+2.
This classic problem can be resolved by using locks that prevent arbitrary interleaving of p and q.
Locks are shared objects that can be held by at most a single thread
within a program at a time. A lock is created by the function
create.
This function returns a new lock, initially not held by any thread. To acquire an existing lock, it is necessary to use the system call lock with the lock as argument. If the lock is held by another thread, the caller is frozen until the lock is released. A lock must be released explicitly by the thread that holds it with the system call unlock.
The lock call behaves like Thread.join with respect to
signals: if the thread receives a signal while executing lock,
the signal will be noted (i.e. the OCaml runtime will be notified
that the signal has arrived), but the thread will continue to wait so
that lock effectively returns only when the lock has been
acquired, and never raises the EINTR exception. The real
treatment of the signal by OCaml will happen only upon the return
from lock.
We can also try to acquire a lock without blocking with the system call trylock
This function returns true if the lock has been acquired and
false otherwise. In the latter case, execution is not suspended
since the lock is not acquired. The thread can therefore do something
else and eventually return and try its luck later.
Incrementing a global counter used by several threads poses a synchronization problem: the instants between reading the value of the counter and writing the incremented value are in a critical region, i.e. two threads cannot be in this region at the same time. The synchronization can easily be managed with a lock.
The sole read operation on the counter poses no problem. It can be performed in parallel with a modification of the counter: the result will simply be the value of the counter just before or just after the modification, both results being consistent.
A common pattern is to hold a lock temporarily during a function call. It is of course necessary to make sure to release the lock at the end of the call, whether the call succeeded or failed. We can abstract this behavior in a library function:
In the preceding example, we could also have written:
An alternative to the model of the server with threads is to start a number of threads in advance which handle requests in parallel.
The tcp_farm_server function behaves like tcp_server but
takes an additional argument which is the number of threads to start,
each of which will become a server at the same address. The advantage
of a pool of threads is to reduce the time to handle each connection
by eliminating the cost of creating a thread for it, since they are
created once and for all.
The only precaution to take is to ensure mutual exclusion around the
accept so that only one of the threads accepts a connection at a
time. The idea is that the treat_connection function performs a
sequential treatment, but it is not a requirement — we can
effectively combine a pool of threads with the creation of new
threads, which can be dynamically adjusted depending on the load.
Acquisition of a lock is an inexpensive operation when it succeeds without blocking. It is generally implemented with a single “test-and-set” instruction provided by all modern processors (plus other small costs that are involved, such as updating caches). However, when the lock is not available, the process must be suspended and rescheduled later, which involves a significant additional cost. We must therefore incur this penalty only for a real suspension of a process in order to give control to another, and not for its potential suspension during the acquisition of a lock. Consequently, we will almost always want to release a lock as soon as possible and take it back later if necessary, rather than simply holding onto the lock. Avoiding these two operations would have the effect of enlarging the critical region and therefore the frequency with which another thread finds itself effectively in competition for the lock and in need of suspension.
Locks reduce interleaving. In return, they increase the risk of deadlock. For example, there is a deadlock if a thread p waits for a lock v held by a thread q which itself waits for a lock u held by p. (In the worst case, a thread waits for a lock that it holds itself.) Concurrent programming is difficult, and guarding against deadlock is not always easy. A simple way of avoiding this situation that is often possible consists of defining a hierarchy among the locks and ensuring that the order in which the locks are acquired dynamically respects the hierarchy: a thread never acquires a lock unless that lock is dominated by all the other locks that the thread already holds.
We modify the http relay developed in section 6.14 so that it services requests using threads.
Intuitively, it suffices to replace the establish_server function
that creates a process clone with a function that creates a
thread. We must however take certain precautions. The challenge
with threads is that they share the entire memory space. We must
therefore ensure that the threads are not “stepping on each
other’s toes” with one undoing what was just done by another.
That typically happens when two threads modify the same mutable
structure in parallel.
In the case of the http server, there are several changes to make.
Let us start by resolving problems with access to resources. The
proxy_service function, described in section 6.14,
handles the treatment of connections. Via the intermediary functions
parse_host, parse_url and parse_request, it calls the
regexp_match function which uses the Str library. However,
this library is not re-entrant (the result of the last search is
stored in a global variable). This example shows that we must beware
of calls to innocent-looking functions that hide potential collisions.
In this case we will not rewrite the Str library but simply
sequentialize its use. It suffices to protect calls to this library
with locks (and there is really no other choice). We must still take
the precaution of releasing the lock when returning from the function
abnormally due to an exception.
To modify the existing code as little as possible, we can just rename
the definition of regexp_match in the Url module as
unsafe_regexp_match and then define regexp_match as a
protected version of unsafe_regexp_match.
The change is rather minimal. It should be noted that the
regexp_match function includes both the expression matching and
the extraction of the matched groups. It would definitely have been
incorrect to protect the Str.string_match and
Str.matched_group functions individually.
Another solution would be to rewrite the analysis functions without using
the Str library. But there is no reason for such a choice, since
synchronizing the library primitives is easy to do and does not turn
out to be a source of inefficiency. Obviously, a better solution
would be for the Str library to be re-entrant in the first place.
The other functions that are called are already re-entrant, in particular
the Misc.retransmit function that allocates different buffers for
each call.
However, there are still some precautions to take regarding error
handling. The handling of a connection by a thread must be robust, as
explained above. In particular, in case of error, the other threads
must not be affected. In other words, the thread must terminate
“normally”, properly closing the connection in question and
going back to accepting other pending connections. We must first of
all replace the call to exit in handle_error because it is
essential not to kill the whole process. A call to Thread.exit
would not be correct either, because thread termination does not close
its (shared) descriptors, the way the system does for process
termination. An error in the handling of a connection would leave the
connection open. The solution consists of raising an Exit
exception that allows the finalization code to do what is required.
We must now protect treat_connection by catching all errors, in
particular Exit but also EPIPE, which can be raised if the
client closes the connection prematurely. We will take care of this
by using a protected function.
Coroutines can be seen as a very particular kind of threads where each process must surrender control explicitly before another can execute. Give an implementation of coroutines using threads.
The functions described in this section are defined in the Condition module.
Synchronization with locks is very simple, but it is not sufficient: locks allow waiting for shared data to be free, but do not allow waiting for the data to have a particular state. Let us replace the example of a counter by a (first-in/first-out) queue shared among several threads. Adding a value to the queue can be synchronized by using a lock as above, since no matter what the state of the queue, we can always add an element. But what about removing an element from the queue? What should be done when the queue is empty? We cannot hold the lock while waiting for the queue to be filled, because that would completely prevent another thread from filling the queue. So it must be released. But how can we know when the queue is no longer empty, except by testing it periodically? This solution, called “busy-waiting”, is definitely not satisfactory. Either it consumes computing cycles unnecessarily (period too short) or else it it is not reactive enough (period too long).
Conditions provide a solution to this problem. A thread that
holds a lock can wait for a condition object until another thread
sends a signal on that condition. As with locks, conditions are
passive structures that can be manipulated by synchronization
functions. They can be created by the create
function.
A process p that already holds a lock v can wait on a
condition c and the lock v with the system call wait.
The process p informs the system that it is waiting on the condition
c and the lock v, then releases the lock v and goes to
sleep. It will not be woken up by the system until another thread q
signals a change on the condition c and the lock v is
available; the process p will then hold the lock v again.
Note: it is an error to call wait c v without holding the lock
v. The behavior of wait c v with respect to signals is the
same as for Mutex.lock.
When a thread signals a change on a condition, it can either ask for all threads waiting on that condition to be woken up (system call broadcast), or else for just one of them to be woken up (system call signal).
Sending a signal or a broadcast on a condition does not require holding a lock (unlike waiting), in the sense that it will not trigger a “system” error. However, it can sometimes be a programming error.
The choice between waking up one thread or all the threads depends on the problem. To consider the example of the queue again, if a thread adds an element to an empty queue, there is no need to wake up all the others, since only one will effectively be able to remove that element. On the other hand, if it adds a number of elements that is either not statically known or very large, it must wake up all the threads. Note that if adding an element to a non-empty queue does not send a signal, then adding an element to an empty queue must send a broadcast, since it could be followed immediately by another addition (without a signal) and therefore behave like a multiple addition. In summary, either send a signal on every addition, or send a broadcast only when adding to an empty queue. The choice between these two strategies is a bet on whether the queue is usually empty (first solution) or usually non-empty (second solution).
Often, one thread knows only an approximation of the reason why another thread is waiting on a condition. It will therefore signal the condition whenever the situation might be what the other thread is waiting for. An awakened thread, therefore, cannot assume that the condition it was waiting is now satisfied. It must, in general, re-test the state of its shared data, and if necessary wait on the condition again. This does not constitute busy-waiting, because it only happens when another thread signals the condition.
Here is another justification for this approach: when a thread has
just produced a lot of some resource and wakes all the others using a
broadcast, nothing prevents the first one that wakes up from
being greedy and exhausting the entire resource. The second one to
wake up must go back to sleep, hoping to be luckier next time.
We can now give a concrete solution for shared queues. The queue
structure defined in the Queue module is extended with a lock and
a non_empty condition.
Addition never blocks, but we must not forget to signal
the non_empty condition when the list is empty beforehand,
because it is possible that someone is waiting on the condition.
Removal is a little more complicated: after acquiring the lock, we
must try to remove an element from the queue. If the queue is empty,
we must wait on the non_empty condition. When awakened, we try
again, knowing that we already have the lock.
As explained above, the broadcast q.non_empty signal
(line 9) is executed by a thread p already in
possession of the lock q.lock.
This implies that a reader thread q executing the take function
cannot be between line 15 and 16
where it would have verified that the queue is empty but not yet have
gone to sleep. In this case, the signal sent by p would be
ineffective and ignored, since q has not gone to sleep yet; but q
would then go to sleep and not be woken up, because p has already
sent its signal.
The lock therefore guarantees that either q is already asleep or
else has not yet tested the state of the queue.
Implement a variant in which the queue is bounded: addition to the queue becomes blocking when the size of the queue reaches a fixed value. (In a concurrent world, we might need this scheme to avoid having a producer that produces endlessly while the consumer is blocked.) Answer.
The functions described in this section are defined in the Event module.
Locks and conditions together allow all forms of synchronization to be expressed. However, their use is not always easy, as shown by the example of the initially simple queue whose synchronization code subsequently turned out to be subtle.
Event-based synchronous communication is a collection of higher-level
communication primitives that tend to facilitate concurrent
programming. The primitives in the Event module were initially
developed by John Reppy as an extension of the Standard ML
language called Concurrent ML [16]. In OCaml, these
primitives are located above the more elementary synchronization of
locks and conditions.
Communication occurs by sending events along channels.
Channels are like “lightweight pipes”: they allow communication
among threads in the same program and take care of synchronization
between producers and consumers. A channel carrying values of type
'a has the type 'a Event.channel. Channels are homogeneous
and therefore always carry values of the same type. A channel is
created with the new_channel function.
Sending or receiving a message is not done directly, but through the intermediary of an event. An elementary event is “sending a message” or “receiving a message”. They are constructed by means of the following primitives:
Construction of a message does not have an immediate effect: it just
creates a data structure describing the action to be done. To make an
event happen, the thread must synchronize with another thread wishing
to make the complementary event happen. The sync primitive
allows a thread to wait for the occurrence of the event passed
as argument.
Thus, to send a value v on the channel c, we can execute
sync (send c v). The thread is suspended until the event occurs,
that is to say until another thread is ready to receive a value on the
channel c. In a symmetric fashion, a thread can wait for a
message on channel c by performing sync (receive c).
There is a competition among all the producers on one hand and all the consumers on the other. For example, if several threads try to send a message on a channel but only one is ready to read it, it is clear that only one producer will make the event occur. The others will remain suspended, without even noticing that another was “served” ahead of them.
The competition can also occur within the same thread.
Multiple events can be combined by the choose primitive.
The resulting event is an offer, in parallel, of the events passed as
arguments, and occurs when exactly one of them occurs. We distinguish
between the offer of an event and its occurrence. The call
sync (choose [e1; e2]) synchronizes by offering a choice of two events
e1 and e2, but only one of the two events will effectively
occur (the offer of the other event will be simultaneously canceled).
The wrap_abort primitive allows to handle an event being
canceled.
The call wrap_abort e f creates an event that is equivalent to
e, but if it is not chosen during synchronization, then the
function f is executed. (This is only interesting when it is
part of a complex event.)
A thread can try to synchronize on an event without blocking (somewhat
like Mutex.try_lock) with poll.
The call poll e offers the event e but if it cannot occur
immediately, it cancels the offer rather than blocking and has no
effect (or more exactly, behaves as if the expression poll e had
been replaced by the value None). By contrast, if the event can
happen immediately, then it behaves as if the thread had done
sync e, except that the value Some v is returned
rather than v.
In section 7.3 the example of the Sieve of Eratosthenes, the communication between different threads is done with pipes as in the original program, using system memory (the pipe) as intermediary. We may think that it is more efficient to communicate directly by using the memory of the process. A simple solution consists of replacing the pipe by a channel on which integers are sent.
Sending integers on the channel is not sufficient, because we must
also be able to detect the end of the stream. The simplest is
therefore to pass elements of the form Some n and to terminate by
sending the value None. To minimize the changes, we use the code
of the example in section 5.2. We simulate pipes and the
functions for reading and writing pipes by channels and functions for
reading and writing channels.
It is sufficient to take the previous version of the program and
change the input/output functions to ones that read and write a channel,
rather than an input/output buffer from the Pervasives library.
For example, we can insert the following code at the beginning of the
program just after the open Unix;; directive:
However, if we compare the efficiency of this version with the previous one, we find that it is twice as slow. Communication of each integer requires a synchronization between two threads and therefore several system calls for acquiring and releasing locks. On the other hand, communication via pipes uses buffered i/o that allows several thousand integers to be exchanged with each system call.
To be fair, one should also provide buffered communication on channels, using the channel only to exchange a packet of integers. The child can accumulate the results in a private queue, to which it can therefore write without synchronization. When the queue is full, or upon an explicit request, it is emptied by synchronizing on the channel. The parent has its own queue that it receives by synchronizing and empties gradually.
Here is a solution:
This version allows us to regain efficiency comparable to (but not better than) the version with pipes.
Compared to the original version with processes and pipes, there are two potential advantages. First, threads are more lightweight and less costly to launch. Second, communication on a channel merely passes a pointer, without copying. But these advantages are not noticeable here, because the number of threads created and the data exchanged are not big enough compared to the cost of system calls and compute time.
In conclusion, we can say that communication between threads has a cost of up to one system call (if the process must be suspended) and the cost can be significantly reduced by buffering communication and sending larger structures less often.
An http server can be subjected to a high, bursty load. To improve response time, we can refine the architecture of an http server by always keeping a dozen threads ready to handle new requests. This means that a thread does not handle only a single request, but a potentially infinite series of requests that it reads from a queue.
To avoid overloading the machine, we can limit the number of threads to a reasonable value beyond which the overhead of managing tasks exceeds the latency for servicing requests (time spent waiting for data on disk, etc.). After that, we can keep some connections waiting to be handled, and then finally we can refuse connections. When the load diminishes and the number of threads is above the “ideal” value, some of them are allowed to die and the others remain ready for the next requests.
Transform the example of section 7.5 into this architecture.
The Unix system was not originally designed to provide support for
threads. However, most modern Unix implementations now offer such
support. Nevertheless, threads remain an add-on that is sometimes
apparent. For example, when using threads it is strongly discouraged
to use fork except when doing exec immediately afterward.
In effect, fork copies the current thread, which becomes a
crippled process that runs believing it has threads when in fact they
do not exist. The parent continues to run normally as before.
The special case of a call to fork where the child immediately
launches another program does not cause the parent any problem.
Luckily, since that is the only way to start other programs!
Inversely, one can do fork (not followed by exec), and then launch
several threads in the child and the parent, without any problem.
When the underlying operating system has threads, OCaml can provide a native implementation of threads, leaving their management to the operating system as much as possible. Each thread then lives in a different Unix process but shares the same address space.
When the system does not provide support for threads, OCaml can emulate them. All the threads then execute in the same Unix process, and their management, including their scheduling, is handled by the OCaml runtime system. However, this implementation is only available when compiling to bytecode.
The OCaml system provides the same programming interface for the native and simulated versions of threads. The implementation of threads is therefore split: one implementation for the emulated version that includes its own task controller, and another implementation that is based on posix (1003.1c) threads and lifts the corresponding library functions to the level of the OCaml language. In the process, the OCaml language handles certain simple administrative tasks and ensures an interface identical to the emulated version. This guarantees that a program compilable on one Unix architecture remains compilable on another Unix architecture. However, whether threads are emulated or native can change the synchronization of calls to the C library, and therefore change, despite everything, the semantics of the program. It is therefore necessary to take certain precautions before believing that a program will behave the same way in these two versions. In this chapter, the discussion mainly concern these two implementations, but recall that by default, we have taken the viewpoint of a native implementation.
To use emulated threads, one must pass the -vmthread option
instead of -thread to the ocamlc compiler. This option is
not accepted by the ocamlopt compiler.
The implementation of threads in OCaml must face one of the peculiarities of the OCaml language: the automatic management of memory and its high consumption of allocated data. The solution adopted, which is the simplest and also generally the most efficient, is to sequentialize the execution of OCaml code in all threads: a lock in the runtime system prevents two threads from executing OCaml code simultaneously. This seems contrary to the whole idea of threads, but it is not, since the lock is released before blocking system calls and reacquired upon return. Other threads can therefore take control at that moment. A special case of such a system call is the call to sched_yield, performed at regular intervals to suspend the running thread and give control to another.
On a multiprocessor machine, the only source of true parallelism comes from the execution of C code and system calls. On a uniprocessor machine, the fact that the OCaml code is sequentialized is not really noticeable.
The programmer cannot rely on this sequentialization, because one thread can give control to another at almost any moment. With one exception, the sequentialization guarantees memory coherence: two threads always have the same view of memory, except perhaps when they execute C code. In effect, the passing of the lock implies a synchronization of the memory: a read operation by one thread occurring after a write operation to the same address by another thread will always return the freshly-written value, with no need for additional synchronization.
Generally speaking, using signals is already delicate with a single thread due to their asynchronous character. It is even more so in the presence of multiple threads because of the addition of new difficulties: which thread should a signal be sent to? To all, to the primary one, or to the one currently running? What happens if one thread sends a signal to another? In fact, threads were implemented before answering these questions, and different implementations can behave differently with respect to signals.
The Thread.join, Mutex.lock, and Condition.wait functions
despite being long system calls, are not interruptible by a signal.
(They cannot therefore fail with the EINTR error.) If a signal
is sent while waiting, it will be received and handled when the call
returns.
The posix standard specifies that the signal handler is shared among all the threads and in contrast the signal mask is private to each thread and inherited upon creation of a thread. But the behavior of threads with respect to signals remains largely underspecified and therefore non-portable.
It is therefore preferable to avoid as much as possible the use of
asynchronous signals (such as sigalrm, sigvtalrm,
sigchld, etc.) with threads. These can be blocked and examined
with Thread.wait_signal.
We can dedicate a thread to signal
handling and nothing else: it can wait for the reception of signals,
undertake the necessary actions, and update certain information
examined by other threads.
In addition, OCaml threads (since version 3.08) use the
sigvtalarm signal internally to implement preemption of threads.
This signal is therefore reserved and must not be used by the program
itself, since there is a risk of interference.