Communication with pipes has some limitations. First, it is local to a machine: with named pipes, communicating processes must run on the same machine and what’s more, with anonymous pipes, they must share a common ancestor. Furthermore, pipes are not very suitable for a particularly useful model of communication: the client-server model. In this model, only one program, the server, has direct access to a shared resource. The other programs, the clients, access the resource by connecting to the server. The server serializes and controls the access to the shared resource. (Example: the x-window windowing system — the shared resources are the screen, the keyboard and the mouse.)
The client-server model is difficult to implement with pipes. The major difficulty is to establish the connection between a client and the server. With anonymous pipes, it is impossible: the server and the client would need a common ancestor that allocated an arbitrarily large number of pipes in advance. With named pipes, the server could read connection requests on a particular pipe. These requests would contain the name of another named pipe created and used by the client to communicate with the server. The problem is to ensure the mutual exclusion of simultaneous connection requests performed by multiple clients.
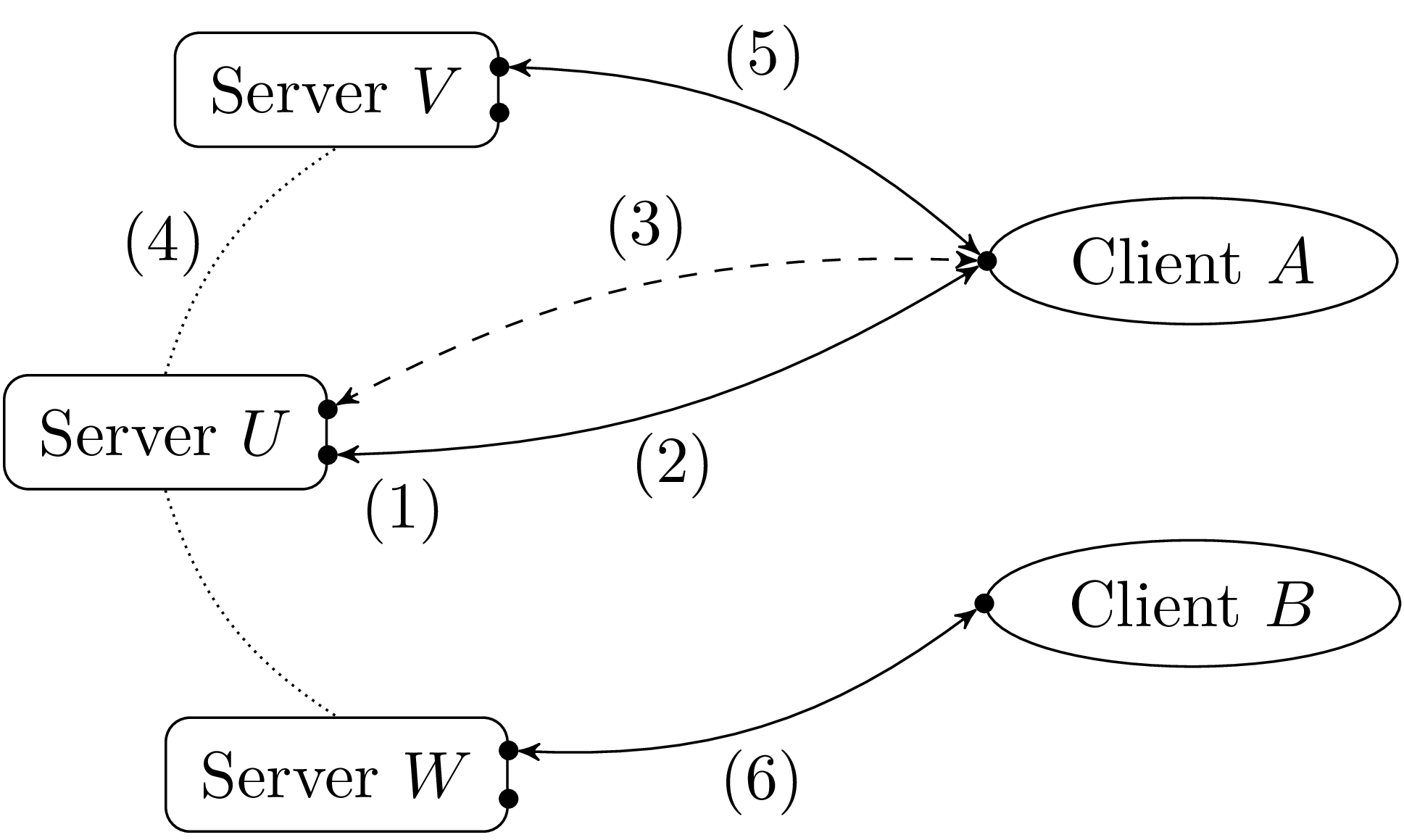
Sockets are a generalization of pipes addressing these issues. The client-server model is shown in figure 3.
In the model described above, the server U and the client A establish a private connection (3) to communicate without interference from other clients. For that reason, this mode of communication is referred to as the connection-oriented mode. If the transaction is short the server can handle the request directly (without forking) through the connection (3). In this case, the next client must wait for the server to be available, either because it is handling the connection (3), or because it explicitly manages several connections via multiplexing.
Sockets also allow a connectionless communication mode. In this mode, less frequently used, the server does not establish a private connection with the client, but responds directly to the client’s requests. We will briefly comment on this model in section 6.10 but in the remainder of this chapter, we mainly describe connection-oriented communication.
Sockets, an extension of pipes, were introduced in bsd 4.2. They are now found on all Unix machines connected to a network. Special system calls are provided to establish connections following the client-server model; they enable local and remote communication between processes in a (nearly) transparent way.
The communication domain of a socket limits the processes (and the format of their address) with which we can communicate on the socket. Different communication domains are available, for example:
129.199.129.1, for example) and a port number on that
machine. Communication is possible between processes running on any
two machines connected to Internet.1
The communication type of a socket indicates whether communication is reliable (no loss or duplication of data) and the way the data is sent and received (a stream of bytes, or a sequence of packets — small blocks of bytes). The communication type constrains the protocol used to transmit data. Different communication types are available, here are three of them with their properties:
| Type | Reliable | Data representation |
| Stream | yes | byte stream |
| Datagram | no | packets |
| Segmented packets | yes | packets |
The “stream” type is very similar to communication with pipes.
It is used most frequently, in particular to transmit unstructured
byte sequences (e.g. rsh). The “segmented packets” type
transmits data as packets: each write delimits a packet, each read
returns at most a packet. It is well suited for message-oriented
communication. The “datagram” type is the closest to the
hardware properties of an Ethernet network: data is transmitted with
packets and there is no guarantee that they reach their
destination. It is the most economical type in terms of network
resources. Some programs use it to transmit data that is not of
crucial importance (e.g. biff); others, to get more network
performance but with the burden of managing data losses manually.
The socket system creates a new socket:
The result is a file descriptor that represents the new
socket. Initially, this descriptor is “disconnected”,
it is not ready to accept any read or write.
The first argument is a value of type socket_domain, it specifies the socket’s communication domain:
PF_UNIX | The Unix domain. |
PF_INET | The Internet domain. |
The second argument, a value of type socket_type, specifies the desired communication type:
SOCK_STREAM | Byte streams, reliable. |
SOCK_DGRAM | Packets, unreliable. |
SOCK_RAW | Direct access to the lower layers of the network. |
SOCK_SEQPACKET | Packets, reliable. |
The third argument is the communication protocol to use. It is usually
0 which selects the default protocol for the given communication
domain and type (e.g. udp for SOCK_DGRAM or
tcp for SOCK_STREAM). Other values allow to use special
protocols, for example icmp (Internet Control Message
Protocol) used by the ping command to send packets which
return automatically to the sender. The numbers for these special protocols
are in the /etc/protocols file or in the protocols table of
the nis (Network Information Service) database, if
any. The system call getprotobyname returns information about a
protocol in a portable manner:
Given the name of a protocol the result is a record
of type protocol_entry. The p_proto field of
this record has the protocol number.
Several socket operations use socket addresses, represented by the variant
type sockaddr:
ADDR_UNIX f is an address in the Unix domain, f is
the name of the corresponding file in the machine’s file
system. ADDR_INET (a,p) is an address in the Internet domain,
a is the Internet address of a machine and p a port
number on this machine.
Internet addresses are represented by the abstract type
inet_addr. The following functions convert strings of the form
128.93.8.2 to values of type inet_addr, and vice versa:
Another way to obtain internet addresses is to look them up by host name in
the /etc/hosts table, the nis database or in domain name
servers. The system call gethostbyname does that. On
modern machines, the domain name servers are consulted first and
/etc/hosts is only used as a fallback but in general that may
depend on the machine’s configuration.
The argument is the host name to look for and the result a record of
type host_entry. The h_addr_list field of this
record is an array of Internet addresses corresponding to the machine
(the same machine can be connected to multiple networks under
different addresses).
Regarding port numbers, the most common services are listed in the
table /etc/services which can be read in a portable manner using
the getservbyname function:
The first argument is the service name ("ftp" for ftp
servers, "smtp" for email, "nntp" for news servers,
"talk" and "ntalk" for commands of that name, etc.) and the
second argument is the name of the protocol: usually "tcp" if the
service is using the stream connection type or "udp" for the
datagram type. The result of getservbyname is a record of type
service_entry whose s_port field contains the
desired number.
To obtain the address of the ftp server
pauillac.inria.fr:
The system call connect establishes a connection with a server on a socket.
The first argument is a socket descriptor and the second argument is the server’s address.
Once the connection is established, calls to write on the
socket descriptor send data to the server and calls to read
receive data from the server. Sockets behave like pipes for read and
write operations. First, read blocks if no data is available and
can return fewer bytes than requested. Second, whenever the server
closes the connection read returns 0 and write sends a
sigpipe signal to the calling process.
connect binds the socket to a local address chosen by the
system. Sometimes, it is preferable to manually choose this address.
This can be done by calling the function bind (see
section 6.7) before connect.
The netstat Unix command lists the current connections on the
machine and their status.
There are two ways to disconnect a socket. The first is to call close on the socket. This closes the read and write sides of the connection, and deallocates the socket. But sometimes this is too brutal, for example we may want to close the connection from the client to the server to indicate an end of file but keep the connection open in the other direction to get remaining data from the server. The system call shutdown allows to close the connection gradually.
The first argument is the descriptor of the socket to close and the second a value of type shutdown_command indicating which direction to close:
SHUTDOWN_RECEIVE | Closes the socket for reading; write
on the other end of the connection will send a sigpipe signal to
the caller. |
SHUTDOWN_SEND | Closes the socket for writing; read on the
other end of the connection returns an end of file. |
SHUTDOWN_ALL | Closes the socket for reading and writing;
unlike close, the socket descriptor is not deallocated.
|
Note that disconnecting a socket can take some time whether done with
close or shutdown.
We program a client command such that client host port
establishes a connection on the port port of the machine named
host, sends on the resulting socket the data it reads on its
standard input and writes the data it receives on its standard output.
For instance, the command
connects to the port 80 of pauillac.inria.fr and sends an
http request for the web page /~remy/.
This command is a “universal” client application in the sense
that it factors out the code to establish a connection common to many
clients and delegates the implementation of the specific protocol to
the program that calls client.
The library function Misc.retransmit fdin fdout reads data on the
descriptor fdin and writes it on fdout. It terminates,
without closing the descriptors, when the end of file is reached on
the input descriptor. Note that retransmit may be interrupted by
a signal.
The serious matter starts here.
We start by determining the Internet address of the machine to which
we want to connect. It can be specified by a host name or in numerical
form, gethostbyname correctly handles both cases. Then, we create
a socket of type stream in the Internet domain with the default protocol
and connect it to the address of the machine.
The process is then cloned with fork. The child process copies
the data from its standard input to the socket. Once the end of
standard input is reached it closes the connection in the sending
direction and terminates. The parent process copies the data it reads
on the socket to its standard output. Once the end of file is reached
on the socket, it closes the standard output, synchronizes with the
child process and terminates.
The connection is closed either by the client or by the server:
sigpipe signal the next time it
tries to write on the socket. This does not however report that the
connection was lost. If that is needed we can ignore
the sigpipe signal by inserting the following line after
line 19:
and the write will raise an EPIPE error instead.
Having seen how a client connects to a server, we now show how a server can provide a service for clients. First we need to associate a particular address to a socket to make it reachable from the network. The system call bind does this:
The first argument is the socket descriptor and the second the address to bind. The constant Internet address inet_addr_any can be used to bind all the Internet addresses that the machine has (it may be on multiple sub-networks).
We then indicate that the socket can accept connections with the system call listen:
The first argument is the socket descriptor and the second is the number of request that can be be put on hold while the server is busy (ranges from a few dozen to several hundreds for large servers). When the number of waiting clients exceeds this number, additional client connection requests fail.
Finally, connection requests on a socket descriptor are received via the system call accept:
When the call returns the socket given in argument is still free and
can accept more connection request. The first component of the result
is a new descriptor connected to the client, everything written
(resp. read) on that socket can be read (resp. is written) on the
socket the client gave to connect. The second component of the
result is the address of the client. It can be used to check that the
client is authorized to connect (for example this is what the
x server does, xhost can be used to add new
authorizations), or to establish a second connection from the server
to the client (as ftp does for each file transfer request).
The general structure of a tcp server is as follows.
The library function Misc.install_tcp_server addr creates a
socket of type stream in the Internet domain with the default protocol
and prepares it to accept new connection requests on the address addr
with bind and listen. Given that this is a library
function, we close the socket in case of an error.
The library function Misc.tcp_server creates a socket with
install_tcp_server and enters an infinite loop. At each iteration
of the loop it waits for a connection request with accept and
treats it with the function treat_connection. Since this is a
library function we restart the accept call if it is
interrupted. We also ignore the signal sigpipe so that unexpected
disconnection raise an EPIPE exception that can be caught by
treat_connection rather than killing the server. Note that it in
any case it is treat_connection’s duty to close the client
descriptor at the end of the connection.
The function treat_connection is also given the descriptor of the
server so that if it forks or or double_forks it can be
closed by the child.
Now suppose we have the following, application specific, service
function that talks to the client end ends by closing the connection:
The server itself can treat each connection sequentially. The
following library function, in Misc, captures this pattern:
However as the server cannot handle any other requests while serving a client,
this scheme is only appropriate for quick services, where the
service function always runs in a short, bounded, amount of time (for
instance, a date server).
Most servers delegate the service to a child process: fork is called
immediately after accept returns. The child process handles the
connection and the parent process immediately retries to accept. We
obtain the following library function in Misc:
Note that it is essential that the parent closes client_sock
otherwise the close made by the child will not terminate the
connection (besides the parent would also quickly run out of
descriptors). The descriptor is also closed if the fork fails, for the
server may eventually decide the error is not fatal and continue to
operate.
Similarly, the child immediately closes the server descriptor on
which the connection request was received. First, it does not need
it. Second, the server may stop accepting new connections before
the child has terminated. The call to exit 0 is important since
it ensures that the child terminates after the execution of the
service and that it does not start to execute the server loop.
So far we ignored the fact that children will become zombie processes
and that we need to recover them. There are two ways to to so. The
simple approach is to have a grandchild process handle the connection
using a double fork (see page ??). This gives the
following library function, also in Misc:
However with this approach the server loses all control on the
grandchild process. It is better to have the processes handling
services and the server in the same process group so that the whole
group can be killed at once to terminate the service. For this reason servers
usually keep the fork treatment but add children recovering code, for
example in the handler of the sigchld signal (see the function
Misc.free_children on page ??).
Sockets have numerous internal parameters that can be tuned: the size of the transfer buffer, the size of the minimum transfer, the behavior on closing, etc.
These parameters have different types, for this reason there are as many getsockopt and setsockopt OCaml functions as there are types. Consult the OCaml documentation of the function getsockopt and its variants to get a detailed list of those options and the posix reference for getsockopt and setsockopt for their exact meaning.
The following two parameters apply only to sockets of type stream in the Internet domain.
In the tcp protocol, the disconnection of a socket is
negotiated and hence takes some time. Normally a call to
close returns immediately, and lets the system
negotiates the disconnection. The code below turns close on the
socket sock into a blocking operation. It blocks either
until all the sent data has been transmitted or until 5 seconds have
passed.
The SO_REUSEADDR option allows the bind system call
to allocate a new socket on a local address immediately after the
socket sock bound on that address is closed (there is however the
risk to get packets intended for the old connection). This option
allows to stop a server and restart it immediately, very useful for
testing purposes.
We program a server command such that:
receives connection requests on the port port and, for each
connection, executes cmd with the arguments arg1 ... argn
and the socket connection as its standard input and output. For
example, if we execute:
on the pomerol machine and the universal client (see
section 6.6) on an other machine as follows:
the client displays the same result as if we had typed:
except that grep is executed on pomerol, and not on the local machine.
This command is a “universal” server in the sense that it factors
out the code common to many server and delegates the implementation of
the specific service and communication protocol to the cmd program it
launches.
The address given to tcp_server contains the Internet address
of the machine running the program; the usual way to get it
(line 11) is by calling
gethostname. But in general many addresses are
referencing the same machine. For instance, the address of the
pauillac machine is 128.93.11.35, it can also be accessed
locally (provided we are already on the pauillac machine) with
the address 127.0.0.1. To provide a service on all the addresses
pointing to this machine, we can use the constant Internet address
inet_addr_any.
The service is handled by a “double fork”. The service
function, executed by the child, redirects standard input and the two
standard output on the connection socket and executes the requested
command (note that the handling of the service cannot be done
sequentially).
The connection is closed without any intervention of the server
program. One of the following cases occurs:
exit when it is done. This closes the standard outputs which
are the last descriptors open for writing on the connection and the
client receives an end of file on its socket.sigpipe signal the next time it tries to write
data on the connection. This may kill the process but is perfectly
acceptable since nothing is now reading the output of this command.sigpipe signal
(or an EPIPE exception) when it tries to write on the
connection.
Writing a server requires more care than writing a client. While the client usually knows the server to which it connects, the server knows nothing about its clients and particularly if the service is public, the client can be “hostile”. The server must therefore guard itself against all pathological cases.
A typical attack is to open connections and leave them open without transmitting requests. After accepting the connection the server is blocked on the socket as long as the client stays connected. An attacker can saturate the service by opening a lot of unused connections. The server must be robust against these attacks: it must only accept a limited number of simultaneous connections to avoid system resources exhaustion and it must terminate connections that remain inactive for too long.
A sequential server handling connections without forking is immediately exposed to this blocking issue. It will be unresponsive for further request even though it does nothing. A solution for a sequential server is to multiplex the connections, but it can be tricky to implement. The solution with a parallel server is more elegant, but it still needs a timeout, for example by programming an alarm (see section 4.2).
The tcp protocol used by most connections of type
SOCK_STREAM works only in connection-oriented mode. Conversely,
the udp protocol used by most connections of type
SOCK_DGRAM always works in connectionless mode, there is
no established connection between the two machines. For this type of
sockets, data is transmitted with the system calls recvfrom
and sendto.
Their interface is similar to read and write, they
return the size of the transferred data. The
call recvfrom also returns the address of the sending machine.
We can call connect on a socket of type SOCK_DGRAM
to obtain a pseudo-connection. This pseudo-connection is just an
illusion, the only effect is that the address passed in argument is
memorized by the socket and becomes the address used for sending and
receiving data (messages coming from other addresses are ignored). It
is possible to call connect more than once to change the address
or disconnect the pseudo-connection by connecting to an invalid
address like 0. In contrast, doing this with a socket of type stream
would generally issue an error.
The system calls recv and send respectively generalize read and write but they work only on socket descriptors.
Their interface is similar to read and write but they add
a list of flags of type msg_flag whose semantics is:
MSG_OOB | Process out-of-band data. |
MSG_DONTROUTE | Short-circuit the default routing table. |
MSG_PEEK | Examines the data without reading it. |
These primitives can be used in connection-oriented mode instead of
read and write or in pseudo-connected mode instead of
recvfrom and sendto.
Examples like the universal client-server are so frequent that the
Unix module provides higher-level functions to establish
or use network services.
The open_connection function opens a connection to the given address
and creates a pair of Pervasives input/output channels on the resulting
socket. Reads and writes on these channels communicate with the server
but since the output channel is buffered we must flush it to ensure
that a request has been really sent. The client can shutdown the
connection abruptly by closing either of the channels (this will close
the socket) or more “cleanly” by calling
shutdown_connection. If the server closes the connection, the
client receives an end of file on the input channel.
A service can be established with the establish_server function.
The function establish_server f addr establishes a service on the
address addr and handles requests with the function f. Each
connection to the server creates a new socket and forks. The child
creates a pair of Pervasives input/output channels on the socket
to communicate with the client and gives them to f to provide the
service. Once f returns the child closes the socket and exits. If
the client closes the connection cleanly, the child gets and end of
file on the input channel and if it doesn’t it may receive a
sigpipe signal when f writes on the output channel. As for the
parent, it has probably already handled another request! The
establish_server function never terminates, except in
case of error (e.g. of the OCaml runtime or the system during
the establishment of the service).
In simple cases (rsh, rlogin, …), the data transmitted
between a client and a server is naturally represented by two streams
of bytes, one from the client to the server and the other in the
reverse direction. In other cases, the data to transmit is more
complex, and requires to be encoded and decoded to/from the streams of
bytes. The client and the server must then agree on a precise
transmission protocol, which specifies the format of requests and
responses exchanged on the connection. Most protocols used by Unix
commands are specified in documents called “rfc”
(request for comments): these documents start as proposals open
for discussion, and gradually become standards over time, as users
adopt the described protocol.2
Most binary protocols transmit data in a compact format, as close as possible to the in-memory representation, in order to minimize the encoding/decoding work needed for transmission and save network bandwidth. Typical examples of protocols of this type are the x-window protocol, which governs exchanges between the x server and x applications, and the nfs protocol (rfc 1094).
Binary protocols usually encode data as follows. An integer or floating point number is represented by its 1, 2, 4, or 8 bytes binary representation. A string by its length as an integer followed by its contents as bytes. A structured object (tuple, record) by the representation of its fields in order. A variable size structure (array, list) by its length as an integer followed by the representation of its elements. If the exact type of data being transmitted in known to a process it can easily recreate it in its memory. When different type of data is exchanged on a socket the data encoding can be preceded by an integer to identify the data that follows.
The XFillPolygon call of the x library, which draws and
fills a polygon, sends a message with the following structure to the
x server:
FillPoly command)
With binary protocols we must pay attention to the computer architecture of the communicating machines. In particular for multi-byte integers, big-endian machines store the most significant byte first (that is, in memory, at the lower-address) and little-endian machines store the least significant byte first. For instance, the 16 bit integer 12345 = 48 × 256 + 57 is represented by the byte 48 at the address n and the byte 57 at the address n+1 on a big-endian machine, and by the byte 57 at the address n and the byte 48 at the address n+1 on a little-endian machine. Hence protocols must precisely specify which convention they use when multi-bytes integers are transmitted. Another option is to allow both and have it specified in the header of the transmitted message.
The OCaml system helps to encode and decode data structures (a procedure called marshalling, serialization or pickling in the literature) by providing two functions to convert an OCaml value into a sequence of bytes and vice versa:
These function are defined to save values to a disk file and get them back but they can also be used to transmit any value on a pipe or a socket. They handle any OCaml values except functions, preserve sharing and circularities inside values and work correctly between machines of different endianness. More information can be found in the Marshal module.
Note that semantically, the type of input_value is incorrect. It
is too general, it is not true that the result of input_value is
of type 'a for any type 'a. The value returned by
input_value belongs to a precise type, and not to all possible
types. But this type cannot be determined at compile time, it depends
on the content of the channel read at runtime. Type-checking
input_value correctly requires an extension to the ML language
known as dynamic objects: values are paired with a representation of
their type allowing to perform runtime type checks. Consult
[15] for a detailed presentation.
If the x-window protocol was written in OCaml, we would
define a variant type request for requests sent to the
server and a reply type for server responses:
The core of the server would be a loop that reads and decodes a request and responds by writing a reply:
The functions of the x library, linked with each application would have the following structure:
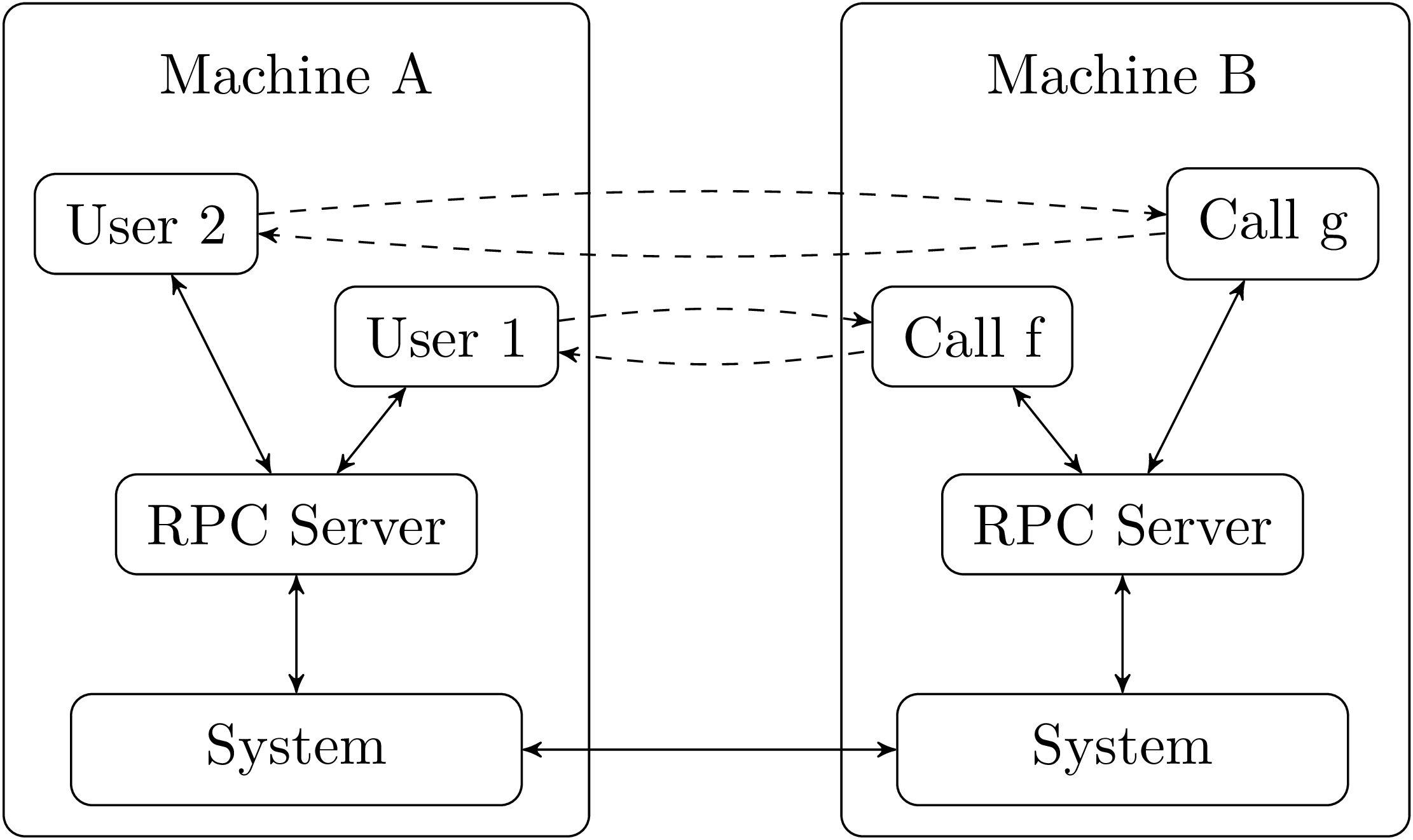
Another typical incarnation of binary protocols is remote procedure
calls (rpc). A user on machine A wants to call a function
f on a machine B. This is obviously not directly possible. It can
be programmed on a case by case basis using the system to open
a connection to the machine B, execute the call and send the
result back to the machine A.
But since this is a common situation, an rpc service can
handle that (see figure 4). An rpc server runs on
both machine A and B. A user on machine A requests the rpc
server on the machine to execute a function on the distant machine
B. The server on A relays the request to the rpc server on
machine B which executes the call to f, sends the result back to
the server on A which gives the result to the user. The point is that
another user can call another function on B by going through the same
server on A. The connection work is shared by the rpc service
installed on the machines A and B and from the perspective of the
users, everything happens as if these calls were simple function calls
(dashed arrows).
Network services where the efficiency of the protocol is not crucial are often “text” protocols. A “text” protocol is in fact a small command language. Requests are command lines, the first word identifies the request type and the possible remaining words the command’s arguments. Responses are also made of one or more lines of text, often starting with a numerical code to identify the kind of response. Here are some “text” protocols:
| Name | Descr. | Purpose |
| smtp (Simple Mail Transfer Protocol) | rfc 821 | Electronic mail |
| ftp (File Transfer Protocol) | rfc 959 | File transfer |
| nttp (Network News Transfer Protocol) | rfc 977 | News reading |
| http/1.0 (HyperText Transfer Protocol) | rfc 1945 | Web navigation |
| http/1.1 (HyperText Transfer Protocol) | rfc 2068 | Web navigation |
The great advantage of these protocols is that the exchanges between
the server and the client are human readable. For example we can just
use the telnet command to talk directly to the server. Invoke
telnet host service where host is the host name on which the
server is running the service service (e.g. http, smtp,
nntp, etc.) and then type in the requests as a client would, the
server’s responses will be printed on standard output. This makes it easier to
understand the protocol. However coding and decoding requests and
responses is more involved than for binary protocols and the message
size also tends to be larger which is less efficient.
Here is an example of an interactive dialog, in the shell, to send an email on an smtp server. The lines preceded by >> go from the client to the server, and are typed in by the user. The lines preceded by << go from the server to the client.
The commands HELO, MAIL and RCPT respectively send to
the server: the name of the client machine, the address of the sender
and the address of the recipient. The DATA command asks to send
the body of the email. The body of the message is then entered and
ended by a line containing the single character '.' (would the body
of the email contain such a line, we just double the initial '.' on
that line, this additional period is then suppressed by the server).
The responses from the server are all made of a 3 digit numerical code
followed by a comment. Responses of the form 5xx indicate an
error and those with 2xx, that everything is fine. When the
client is a real program it only interprets the response code, the comment is
only to help the person who develops the mail system.
The http protocol (HyperText Transfer Protocol) is primarily used to read documents over the famous “world wide web”. This domain is a niche area of client-server examples: between the client that reads a page and the server that writes it there is a myriad of intermediary relays that act as virtual servers for the real client or delegated clients for the real server. These relay often provide additional service like caching, filtering, etc..
There are several versions of the http protocol. To allow us to focus on the essentials, namely the architecture of clients or relays, we use the simple protocol inherited from the very first versions of the protocol. Even if dust-covered it is still understood by most servers. At the end of the section we describe a more modern, but also more complex, version which is needed to make real tools to explore the web. We do however leave the translation of the examples to this new version as an exercise.
Version 1.0 of the http protocol specified in rfc 1945 defines simple requests of the form:
where sp represents a space and crlf the
string "\r\n" (“return” followed by
“linefeed”). The response to a simple request is also
simple: the content of the url is sent directly, without any
headers and the end of the request is signaled by the end of file,
which closes the connection. This form of request, inherited from
version 0.9 of the protocol, limits the connection to a single
request.
We write a geturl program that takes a single argument, a url,
retrieves the resource it denotes on the web and displays it.
The first task is to parse the url to extract the name of the
protocol (here, necessarily "http"), the address of the server,
the optional port and the absolute path of the document on the
server. This is done with Str, OCaml’s regular
expression library.
Sending a simple request is a trivial task, as the following function shows.
Note that the url can be complete, with the address and port of the server, or just contain the requested path on the server.
Reading the response is even easier, since only the document is
returned, without any additional information. If there’s an error in
the request, the error message returned by the server as an
html document. Thus we just print the response with the
function Misc.retransmit without indicating whether this is an
error or the desired document. The rest of the program establishes the
connection with the server.
We conclude, as usual, by parsing the command line.
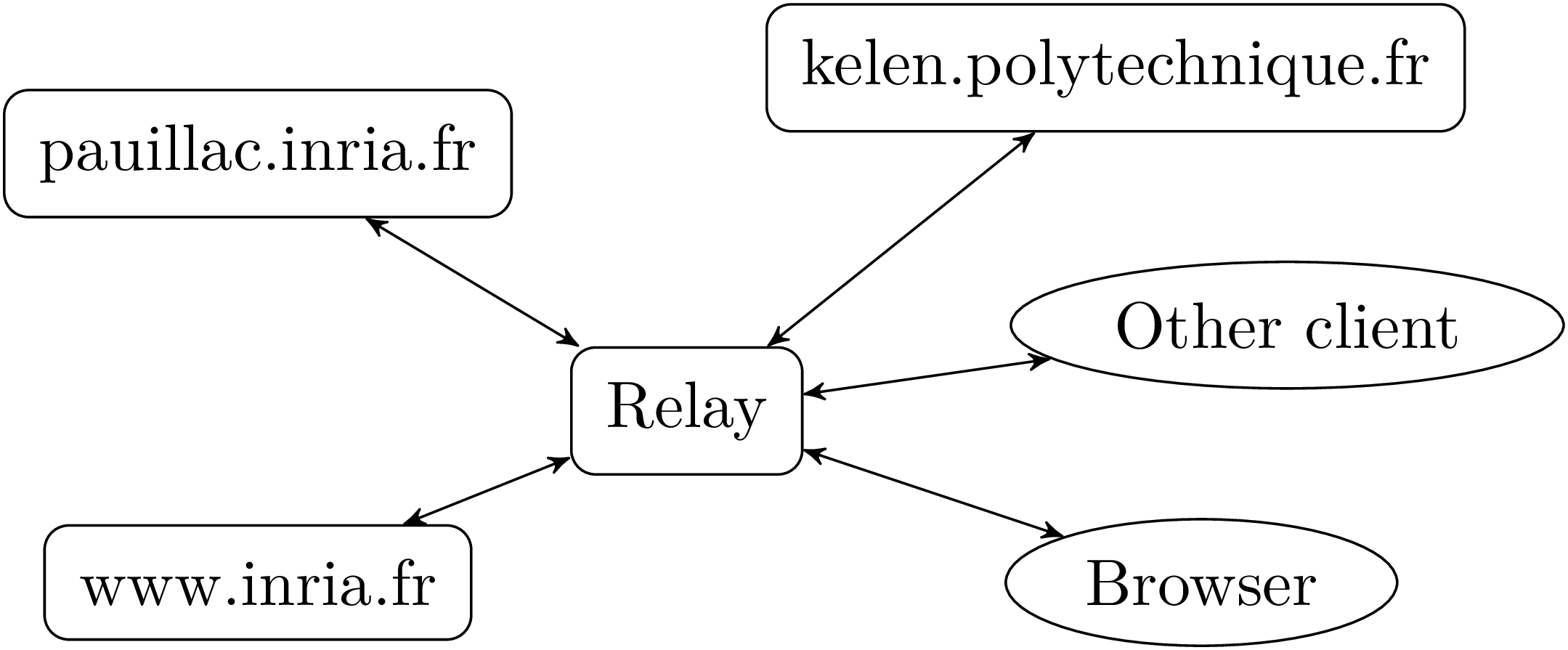
We program an http relay (or proxy), which is a server that redirects http requests from a client to another server (or relay…) and forwards responses from that server back to the client.
The role of a relay is shown in in figure 5. When a client uses a relay, it addresses its requests to the relay rather than to the individual http servers located around the world. A relay has multiple advantages. It can store the responses to the most recent or frequent requests and serve them without querying the remote server (e.g. to avoid network overload or if the server is down). It can filter the responses (e.g. to remove advertisements or image, etc.). It can also simplify the development of a program by making it see the whole world wide web through a single server.
The proxy port command launches the server on the port port
(or if omitted, on the default port for http). We reuse the code of
the get_url function (we assume that the functions above are
available in a Url module). It only remains to write the code to
analyze the requests and set up the server.
We establish the service with the establish_server
function, thus we just need to define the function to handle a
connection:
and the rest of the program just establishes the service:
Simple http requests need one connection per request. This is inefficient because most requests on a server are followed by others (e.g. if a client gets a web page with images, it will subsequently request the images) and the time to establish a connection can easily exceed the time spent in handling the request itself (chapter 7 show how we can reduce this by handling the requests with threads rather than processes). Version 1.1 of the http described in rfc 2068 uses complex requests that allow to make multiple requests on a single connection3.
In complex requests, the server precedes every response with a header describing the format of the response and possibly the size of the document transmitted. The end of the document is no longer indicated by an end of file, since we know its size. The connection can therefore stay open to handle more requests. Complex requests have the following form:
The header part defines a list of key-value fields with
the following syntax:
Superfluous spaces are allowed around the ':' separator and any
space can always be replaced by a tab or a sequence of spaces. The
header fields can also span several lines: in this case, and in this
case only, the crlf end of line lexeme is immediately
followed by a space sp. Finally, uppercase and lowercase
letters are equivalent in the keyword of fields and in the values of
certain fields.
Mandatory and optional fields depend on the type of request. For
instance, a GET request must have a field indicating the
destination machine:
For this type of request, we may also request, using the optional field If-Modified, that the document be returned only if it has been modified since a given date.
The number of fields in the header is not fixed in
advance but indicated by the end of the header: a line
containing only the characters crlf.
Here is a complete request (on each line an implicit \n follows
the \r):
A response to a complex request is also a complex response. It contains a status line, a header, and the body of the response, if any.
The fields of a response header have a syntax similar to that of a request but the required and optional fields are different (they depend on type of request and the status of the response — see the full documentation of the protocol).
The body of the response can be transmitted in a
single block, in chunks or be empty:
Content-Length field specifying in decimal
ascii notation the number of bytes in the body. Transfer-Encoding
field with the value “chunked”. The body is then a set of chunks
and ends with an empty chunk. A chunk is of the form:
size is the size of the chunk in hexadecimal
notation and chunk is a chunk of the response body of
the given size (the part between [ and ]
is optional and can safely be ignored). The last, empty, chunk is
always of the following form:
Content-Length field and
that it is not chunked, the body is empty (for instance, a
response to a request of type HEAD contains only a header).
Here is an example of a single block response:
The status 200 indicates that the request was successful. A
301 means the url was redirected to another url defined in
the Location field of the response. The 4XX statuses
indicate errors on the client side while 5XX errors on the server
side.
Add a cache to the relay. Pages are saved on the hard drive and when a requested page is available in the cache, it is served unless too old. In that case the server is queried again and the cache updated.
Write a program wget such that wget u1 u2 ... un makes the
requests u1, u2, …, un and saves the responses in
the files ./m1/p1, ./m2/p2, …, ./mn/pn where
mi and pi are respectively the name of the server and the
absolute path of the request ui. The program should take
advantage of the protocol to establish a single connection to a
machine m when it is the same for consecutive requests.
Permanent url redirections
should be followed. The following options can also be added:
-N | Do not download the url if the file ./mi/ui
does not exist or is older than the url. |
-r | Download recursively all the urls embedded in the responses which are documents in html format. |