The term “file” in Unix covers several types of objects:
The file concept includes both the data contained in the file and information about the file itself (also called meta-data) like its type, its access rights, the latest access times, etc.
To a first approximation, the file system can be considered to be a tree. The root is
represented by '/'. The branches are labeled by (file) names,
which are strings of any characters excluding '\000' and '/'
(but it is good practice to also avoid non-printing characters and
spaces). The non-terminal nodes are directories: these nodes
always contain two branches . and .. which respectively
represent the directory itself and the directory’s parent. The other
nodes are sometimes called files, as opposed to directories,
but this is ambiguous, as we can also designate any node as a
“file”. To avoid all ambiguity we refer to them as
non-directory files.
The nodes of the tree are addressed by paths. If the start of the path
is the root of the file hierarchy, the path is absolute, whereas if the
start is a directory it is relative. More precisely, a relative
path is a string of file names separated by the character
'/'. An absolute path is a relative path preceded by the
the character '/' (note the double use of this character both as
a separator and as the name of the root node).
The Filename module handles paths in a portable
manner. In particular, concat concatenates paths without
referring to the character '/', allowing the code to function equally
well on other operating systems (for example, the path separator character
under Windows is '\'). Similarly, the Filename module
provides the string values current_dir_name and
parent_dir_name to represent the branches
. and .. The functions basename and
dirname return the prefix d and the suffix
b from a path p such that the paths p and
d/b refer to the same file, where d is the directory in
which the file is found and b is the name of the file. The
functions defined in Filename operate only on paths,
independently of their actual existence within the file hierarchy.
In fact, strictly speaking, the file hierarchy is not a tree. First
the directories . and .. allow a directory to refer to
itself and to move up in the hierarchy to define paths leading from a
directory to itself. Moreover, non-directory files can have many
parents (we say that they have many hard links). Finally,
there are also symbolic links which can be seen as
non-directory files containing a path. Conceptually, this path can be
obtained by reading the contents of the symbolic link like an ordinary
file. Whenever a symbolic link occurs in the middle of a path we have
to follow its path transparently. If s is a symbolic link whose
value is the path l, then the path p/s/q represents the file
l/q if l is an absolute path or the file p/l/q if
l is a relative path.
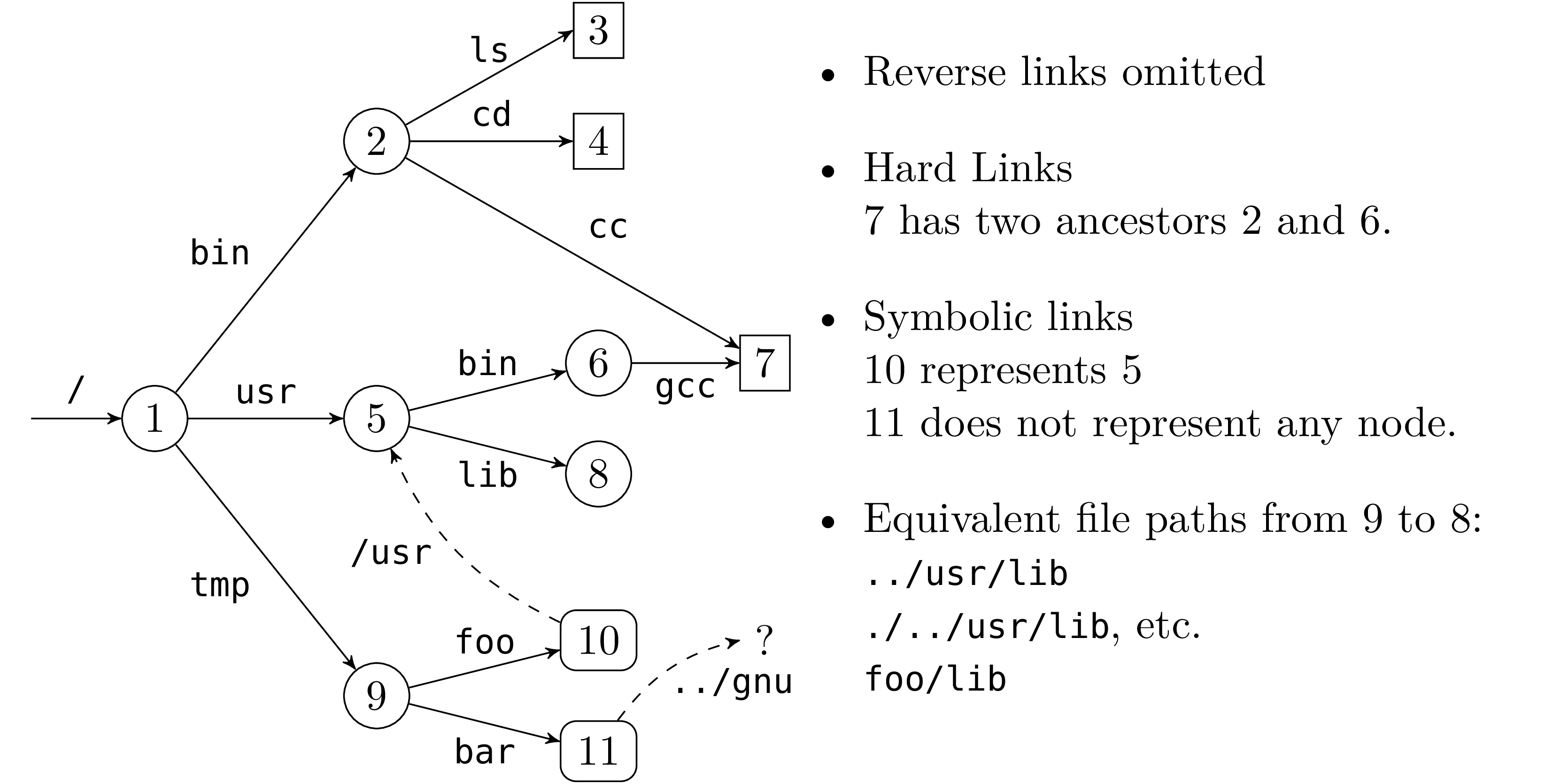
Figure 1 gives an example of a file hierarchy. The
symbolic link 11 corresponding to the path /tmp/bar whose
path value is the relative path ../gnu, does not refer to any
existing file in the hierarchy (at the moment).
In general, a recursive traversal of the hierarchy will terminate if the following rules are respected:
. and .. are ignored.
But if symbolic links are followed we are traversing a graph and we need to keep track of the nodes we have already visited to avoid loops.
Each process has a current working directory. It is returned by the
function getcwd and can be changed with
chdir. It is also possible to constrict the
view of the file hierarchy by calling
chroot p. This makes the node p, which
should be a directory, the root of the restricted view of the
hierarchy. Absolute file paths are then
interpreted according to this new root p (and of course .. at the
new root is p itself).
There are two ways to access a file. The first is by its file
name (or path name) in the file system hierarchy. Due to
hard links, a file can have many different names. Names are values of
type string. For example the system calls unlink,
link, symlink and rename all operate at
the file name level.
Their effect is as follows:
unlink f erases the file f like the Unix command
rm -f f.
link f1 f2 creates a hard link named f2 to
the file f1 like the command ln f1 f2.
symlink f1 f2 creates a symbolic link named f2 to the file
f1 like the command ln -s f1 f2.
rename f1 f2 renames the file f1 to f2
like the command mv f1 f2.
The second way of accessing a file is by a file descriptor. A descriptor represents a pointer to a file along with other information like the current read/write position in the file, the access rights of the file (is it possible to read? write?) and flags which control the behavior of reads and writes (blocking or non-blocking, overwrite, append, etc.). File descriptors are values of the abstract type file_descr.
Access to a file via its descriptor is independent from the access via its name. In particular whenever we get a file descriptor, the file can be destroyed or renamed but the descriptor still points on the original file.
When a program is executed, three descriptors are allocated and
tied to the variables stdin, stdout and stderr of the
Unix module:
They correspond, respectively, to the standard input, standard output and standard error of the process.
When a program is executed on the command line without any
redirections, the three descriptors refer to the terminal. But if,
for example, the input has been redirected using the shell expression
cmd < f, then the descriptor stdin refers to the file named f
during the execution of the command cmd. Similarly, cmd > f
and cmd 2> f respectively bind the descriptors stdout and
stderr to the file named f during the execution of the
command.
The system calls stat, lstat and fstat return the meta-attributes of a file; that is, information about the node itself rather than its content. Among other things, this information contains the identity of the file, the type of file, the access rights, the time and date of last access and other information.
The system calls stat and lstat take a file name as an
argument while fstat takes a previously opened descriptor and
returns information about the file it points to. stat and
lstat differ on symbolic links : lstat returns information
about the symbolic link itself, while stat returns information
about the file that the link points to. The result of these three
calls is a record of type stats whose fields are
described in table 1.
| Field name | Description | ||||||||||||||
st_dev : int | The id of the device on which the file is stored. | ||||||||||||||
st_ino : int | The id of the file (inode number) in its partition.
The pair (st_dev, st_ino) uniquely identifies the file
within the file system. | ||||||||||||||
st_kind : file_kind | The file type. The type file_kind is an enumerated type
whose constructors are:
| ||||||||||||||
st_perm : int | Access rights for the file | ||||||||||||||
st_nlink : int | For a directory: the number of entries in the directory. For others: the number of hard links to this file. | ||||||||||||||
st_uid : int | The id of the file’s user owner. | ||||||||||||||
st_gid : int | The id of the file’s group owner. | ||||||||||||||
st_rdev : int | The id of the associated peripheral (for special files). | ||||||||||||||
st_size : int | The file size, in bytes. | ||||||||||||||
st_atime : int | Last file content access date (in seconds from January 1st 1970, midnight, gmt). | ||||||||||||||
st_mtime : int | Last file content modification date (idem). | ||||||||||||||
st_ctime : int | Last file state modification date: either a
write to the file or a change in access rights, user or group owner,
or number of links.
| ||||||||||||||
stats structureA file is uniquely identified by the pair made of its device number
(typically the disk partition where it is located) st_dev and its
inode number st_ino.
A file has one user owner st_uid and one group owner
st_gid. All the users and groups
on the machine are usually described in the
/etc/passwd and /etc/groups files. We can look up them by
name in a portable manner with the functions getpwnam and
getgrnam or by id with
getpwuid and getgrgid.
The name of the user of a running process and all the groups to which it belongs can be retrieved with the commands getlogin and getgroups.
The call chown changes the owner (second argument) and the group (third argument) of a file (first argument). If we have a file descriptor, fchown can be used instead. Only the super user can change this information arbitrarily.
Access rights are encoded as bits in an integer, and the type
file_perm is just an abbreviation for the type
int. They specify special bits and read, write and
execution rights for the user owner, the group owner and the other
users as vector of bits:
| Special | User | Group | Other | ||||||||
| – | – | – | – | – | – | – | – | – | – | – | – |
OoSUGO
| |||||||||||
where in each of the user, group and other fields, the order of bits
indicates read (r), write (w) and execute (x) rights.
The permissions on a file are the union of all these individual
rights, as shown in table 2.
| Bit (octal) | Notation ls -l | Access right |
0o100 | --x------ | executable by the user owner |
0o200 | -w------- | writable by the user owner |
0o400 | r-------- | readable by the user owner |
0o10 | -----x--- | executable by members of the group owner |
0o20 | ----w---- | writable by members of the group owner |
0o40 | ---r---- | readable by members of the group owner |
0o1 | --------x | executable by other users |
0o2 | -------w- | writable by other users |
0o4 | ------r-- | readable by other users |
0o1000 | --------t | the bit t on the group (sticky bit) |
0o2000 | -----s--- | the bit s on the group (set-gid) |
0o4000 | --s------ | the bit s on the user (set-uid) |
For files, the meaning of read, write and execute permissions is
obvious. For a directory, the execute permission means the right to
enter it (to chdir to it) and read permission the right to list
its contents. Read permission on a directory is however not needed to
read its files or sub-directories (but we then need to know their
names).
The special bits do not have meaning unless the x bit is set (if
present without x set, they do not give additional rights). This
is why their representation is superimposed on the bit x and
the letters S and T are used instead of s and t
whenever x is not set. The bit t allows sub-directories to
inherit the permissions of the parent directory. On a directory,
the bit s allows the use of the directory’s uid or gid rather
than the user’s to create directories. For an executable file,
the bit s allows the changing at execution time of the user’s
effective identity or group with the system calls setuid
and setgid.
The process also preserves its original identities unless
it has super user privileges, in which case setuid and
setgid change both its effective and original user and group
identities. The original identity is preserved to allow
the process to subsequently recover it as its effective identity
without needing further privileges. The system calls getuid and
getgid return the original identities and
geteuid and getegid return the effective identities.
A process also has a file creation mask encoded the same way file permissions are. As its name suggests, the mask specifies prohibitions (rights to remove): during file creation a bit set to 1 in the mask is set to 0 in the permissions of the created file. The mask can be consulted and changed with the system call umask:
Like many system calls that modify system variables, the modifying function returns the old value of the variable. Thus, to just look up the value we need to call the function twice. Once with an arbitrary value to get the mask and a second time to put it back. For example:
File access permissions can be modified with the system calls chmod and fchmod:
and they can be tested “dynamically” with the system call access:
where requested access rights to the file are specified by a list of
values of type access_permission whose meaning is
obvious except for F_OK which just checks for the file’s
existence (without checking for the other rights). The function
raises an error if the access rights are not granted.
Note that the information inferred by access may be more
restrictive than the information returned by lstat because a file
system may be mounted with restricted rights — for example in
read-only mode. In that case access will deny a write permission
on a file whose meta-attributes would allow it. This is why we
distinguish between “dynamic” (what a process can actually do)
and “static” (what the file system specifies) information.
Only the kernel can write in directories (when files are created). Thus opening a directory in write mode is prohibited. In certain versions of Unix a directory may be opened in read only mode and read with read, but other versions prohibit it. However, even if this is possible, it is preferable not to do so because the format of directory entries vary between Unix versions and is often complex. The following functions allow reading a directory sequentially in a portable manner:
The system call opendir returns a directory descriptor for a
directory. readdir reads the next entry of a descriptor, and
returns a file name relative to the directory or raises the exception
End_of_file if the end of the directory is
reached. rewinddir repositions the descriptor at the
beginning of the directory and closedir closes the directory
descriptor.
The following library function, in Misc, iterates a
function f over the entries of the directory dirname.
To create a directory or remove an empty directory, we have mkdir and rmdir:
The second argument of mkdir determines the access rights of the
new directory. Note that we can only remove a directory that is
already empty. To remove a directory and its contents, it is thus
necessary to first recursively empty the contents of the directory and
then remove the directory.
The Unix command find lists the files of a hierarchy matching
certain criteria (file name, type and permissions etc.). In this
section we develop a library function Findlib.find which
implements these searches and a command find that provides a version
of the Unix command find that supports the options -follow
and -maxdepth.
We specify the following interface for Findlib.find:
The function call
traverses the file hierarchy starting from the roots specified in the
list roots (absolute or relative to the current directory of the
process when the call is made) up to a maximum depth depth and following
symbolic links if the flag follow is set. The paths found under
the root r include r as a prefix. Each found path p is
given to the function action along with the data returned by
Unix.lstat p (or Unix.stat p if follow is true).
The function action returns a boolean indicating, for
directories, whether the search should continue for its contents (true)
or not (false).
The handler function reports traversal errors of type
Unix_error. Whenever an error occurs the arguments of the
exception are given to the handler function and the traversal
continues. However when an exception is raised by the functions
action or handler themselves, we immediately stop the
traversal and let it propagate to the caller. To propagate an
Unix_error exception without catching it like a traversal error,
we wrap these exceptions in the Hidden exception (see
hide_exn and reveal_exn).
A directory is identified by the id pair (line 12)
made of its device and inode number. The list visiting keeps
track of the directories that have already been visited. In fact
this information is only needed if symbolic links are followed
(line 21).
It is now easy to program the find command. The essential part of
the code parses the command line arguments with the Arg
module.
Although our find command is quite limited, the library
function FindLib.find is far more general, as the following
exercise shows.
Use the function FindLib.find to write a command
find_but_CVS equivalent to the Unix command:
which, starting from the current directory, recursively prints
files without printing or entering directories whose name is CVS.
Answer.
The function getcwd is not a system call but is defined in the
Unix module. Give a “primitive” implementation of
getcwd. First describe the principle of your algorithm with words
and then implement it (you should avoid repeating the same system
call).
Answer.
The openfile function allows us to obtain a descriptor for
a file of a given name (the corresponding system call
is open, however open is a keyword in OCaml).
The first argument is the name of the file to open. The second argument, a list of flags from the enumerated type open_flag, describes the mode in which the file should be opened and what to do if it does not exist. The third argument of type file_perm defines the file’s access rights, should the file be created. The result is a file descriptor for the given file name with the read/write position set to the beginning of the file.
The flag list must contain exactly one of the following flags:
O_RDONLY | Open in read-only mode. |
O_WRONLY | Open in write-only mode. |
O_RDWR | Open in read and write mode. |
These flags determine whether read or write calls can be done on the
descriptor. The call openfile fails if a process requests an open
in write (resp. read) mode on a file on which it has no right to
write (resp. read). For this reason O_RDWR should not be used
systematically.
The flag list can also contain one or more of the following values:
O_APPEND | Open in append mode. |
O_CREAT | Create the file if it does not exist. |
O_TRUNC | Truncate the file to zero if it already exists. |
O_EXCL | Fail if the file already exists. |
O_NONBLOCK | Open in non-blocking mode. |
O_NOCTTY | Do not function in console mode. |
O_SYNC | Perform the writes in synchronous mode. |
O_DSYNC | Perform the data writes in synchronous mode. |
O_RSYN | Perform the reads in synchronous mode. |
The first group defines the behavior to follow if the file exists or not. With:
O_APPEND, the read/write position will be set at the end of
the file before each write. Consequently any written data will be
added at the end of file. Without O_APPEND, writes occur at the
current read/write position (initially, the beginning of the file).O_TRUNC, the file is truncated when it
is opened. The length of the file is set to zero and the bytes
contained in the file are lost, and writes start from an empty file.
Without O_TRUNC, the writes are made at the start of the file
overwriting any data that may already be there.O_CREAT, creates the file if it does not exist. The created
file is empty and its access rights are specified by the third argument
and the creation mask of the process (the mask can be retrieved
and changed with umask).O_EXCL, openfile fails if the file already exists.
This flag, used in conjunction with O_CREAT allows to use
files as locks1. A process
which wants to take the lock calls openfile on the file with
O_EXCL and O_CREAT. If the file already exists, this means
that another process already holds the lock and openfile raises
an error. If the file does not exist openfile returns without
error and the file is created, preventing other processes from
taking the lock. To release the lock the process calls
unlink on it. The creation of a file is an atomic operation: if
two processes try to create the same file in parallel with the
options O_EXCL and O_CREAT, at most one of them can
succeed. The drawbacks of this technique is that a process must
busy wait to acquire a lock that is currently held and
the abnormal termination of a process holding a lock may never
release it.
Most programs use 0o666 for the third argument
to openfile. This means rw-rw-rw- in symbolic notation.
With the default creation mask of 0o022, the
file is thus created with the permissions rw-r--r--. With a more
lenient mask of 0o002, the file is created with the permissions
rw-rw-r--.
To read from a file:
The third argument can be anything as O_CREAT is not specified, 0
is usually given.
To write to an empty a file without caring about any previous content:
If the file will contain executable code (e.g. files
created by ld, scripts, etc.), we create it with execution permissions:
If the file must be confidential (e.g. “mailbox” files where
mail stores read messages), we create it with write permissions
only for the user owner:
To append data at the end of an existing file or create it if it doesn’t exist:
The O_NONBLOCK flag guarantees that if the file is a named pipe
or a special file then the file opening and subsequent reads and
writes will be non-blocking.
The O_NOCTYY flag guarantees that if the file is a control
terminal (keyboard, window, etc.), it won’t become the controlling
terminal of the calling process.
The last group of flags specifies how to synchronize read and write operations. By default these operations are not synchronized. With:
O_DSYNC, the data is written synchronously such that
the process is blocked until all the writes have been done
physically on the media (usually a disk).
O_SYNC, the file data and its meta-attributes are written
synchronously.
O_RSYNC, with O_DSYNC specifies that the data reads are
also synchronized: it is guaranteed that all current writes
(requested but not necessarily performed) to the file are really
written to the media before the next read. If O_RSYNC is
provided with O_SYNC the above also applies to meta-attributes
changes.
The system calls read and write read and write
bytes in a file. For historical reasons, the system
call write is provided in OCaml under the name
single_write:
The two calls read and single_write have the same
interface. The first argument is the file descriptor to act on. The
second argument is a string which will hold the read bytes (for
read) or the bytes to write (for single_write). The third
argument is the position in the string of the first byte to be written
or read. The fourth argument is the number of the bytes to be read or
written. In fact the third and fourth argument define a sub-string of
the second argument (the sub-string should be valid, read and
single_write do not check this).
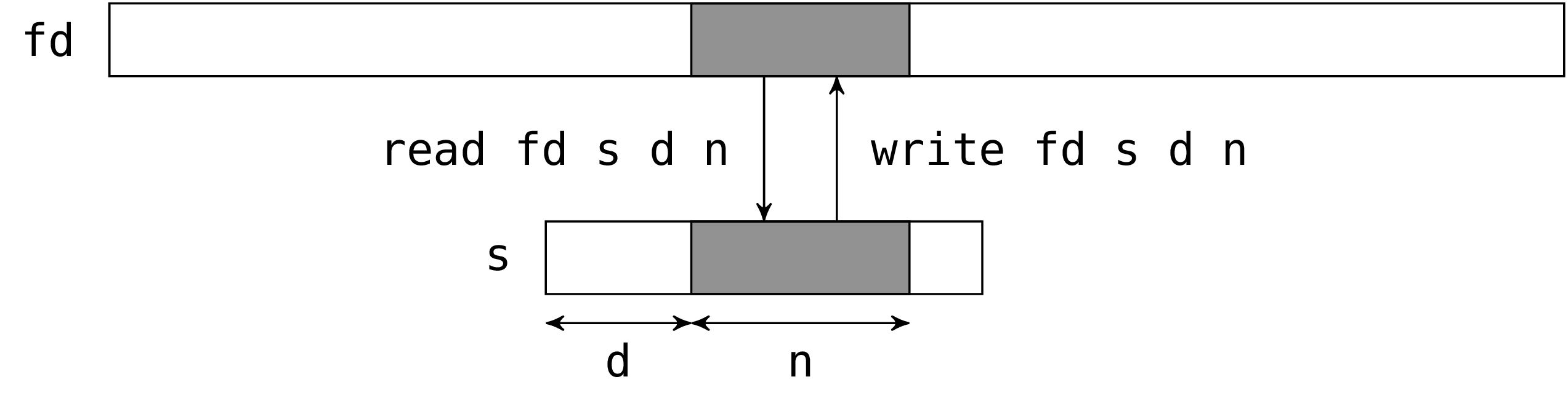
read and single_write return the number of bytes actually
read or written.
Reads and write calls are performed from the file descriptor’s current
read/write position (if the file was opened in O_APPEND mode,
this position is set at the end of the file prior to any
write). After the system call, the current position is advanced by
the number of bytes read or written.
For writes, the number of bytes actually written is usually the number of bytes requested. However there are exceptions: (i) if it is not possible to write the bytes (e.g. if the disk is full) (ii) the descriptor is a pipe or a socket open in non-blocking mode (iii) due to OCaml, if the write is too large.
The reason for (iii) is that internally OCaml uses auxiliary
buffers whose size is bounded by a maximal value. If this value is
exceeded the write will be partial. To work around this problem
OCaml also provides the function write which
iterates the writes until all the data is written or an error occurs.
The problem is that in case of error there’s no way to know the number
of bytes that were actually written. Hence single_write should be
preferred because it preserves the atomicity of writes (we know
exactly what was written) and it is more faithful to the original Unix
system call (note that the implementation of single_write is
described in section 5.7).
Assume fd is a descriptor open in write-only mode.
writes the characters "lo worl" in the corresponding file,
and returns 7.
For reads, it is possible that the number bytes actually read is
smaller than the number of requested bytes. For example when the end
of file is near, that is when the number of bytes between the current
position and the end of file is less than the number of requested
bytes. In particular, when the current position is at the end of file,
read returns zero. The convention “zero equals end of
file” also holds for special files, pipes and sockets. For example,
read on a terminal returns zero if we issue a ctrl-D on the
input.
Another example is when we read from a terminal. In that case,
read blocks until an entire line is available. If the line length
is smaller than the requested bytes read returns immediately with
the line without waiting for more data to reach the number of
requested bytes. (This is the default behavior for terminals, but it
can be changed to read character-by-character instead of
line-by-line, see section 2.13 and the type
terminal_io for more details.)
The following expression reads at most 100 characters from standard input and returns them as a string.
The function really_read below has the same interface as
read, but makes additional read attempts to try to get
the number of requested bytes. It raises the exception
End_of_file if the end of file is reached while doing this.
The system call close closes a file descriptor.
Once a descriptor is closed, all attempts to read, write, or do
anything else with the descriptor will fail. Descriptors should be
closed when they are no longer needed; but it is not mandatory. In
particular, and in contrast to Pervasives’
channels, a file descriptor doesn’t need to be closed to ensure that
all pending writes have been performed as write requests made with
write are immediately transmitted to the kernel. On the other
hand, the number of descriptors allocated by a process is limited by
the kernel (from several hundreds to thousands). Doing a close on
an unused descriptor releases it, so that the process does not run out
of descriptors.
We program a command file_copy which, given two arguments
f1 and f2, copies to the file f2 the bytes contained
in f1.
The bulk of the work is performed by the the function file_copy.
First we open a descriptor in read-only mode on the input file and
another in write-only mode on the output file.
If the output file already exists, it is truncated (option
O_TRUNC) and if it does not exist it is created (option
O_CREAT) with the permissions rw-rw-rw- modified by the creation
mask. (This is unsatisfactory: if we copy an executable file, we would
like the copy to be also executable. We will see later how to give
a copy the same permissions as the original.)
In the copy_loop function we do the copy by blocks of
buffer_size bytes. We request buffer_size bytes to read. If
read returns zero, we have reached the end of file and the copy
is over. Otherwise we write the r bytes we have read in the
output file and start again.
Finally, we close the two descriptors. The main program copy
verifies that the command received two arguments and passes them to
the function file_copy.
Any error occurring during the copy results in a Unix_error
caught and displayed by handle_unix_error. Example of errors
include inability to open the input file because it does not
exist, failure to read because of restricted permissions, failure to
write because the disk is full, etc.
Add an option -a to the program, such that
file_copy -a f1 f2 appends the contents of f1 to the end of
the file f2.
Answer.
In the example file_copy, reads were made in blocks of 8192
bytes. Why not read byte per by byte, or megabyte per by megabyte?
The reason is efficiency.
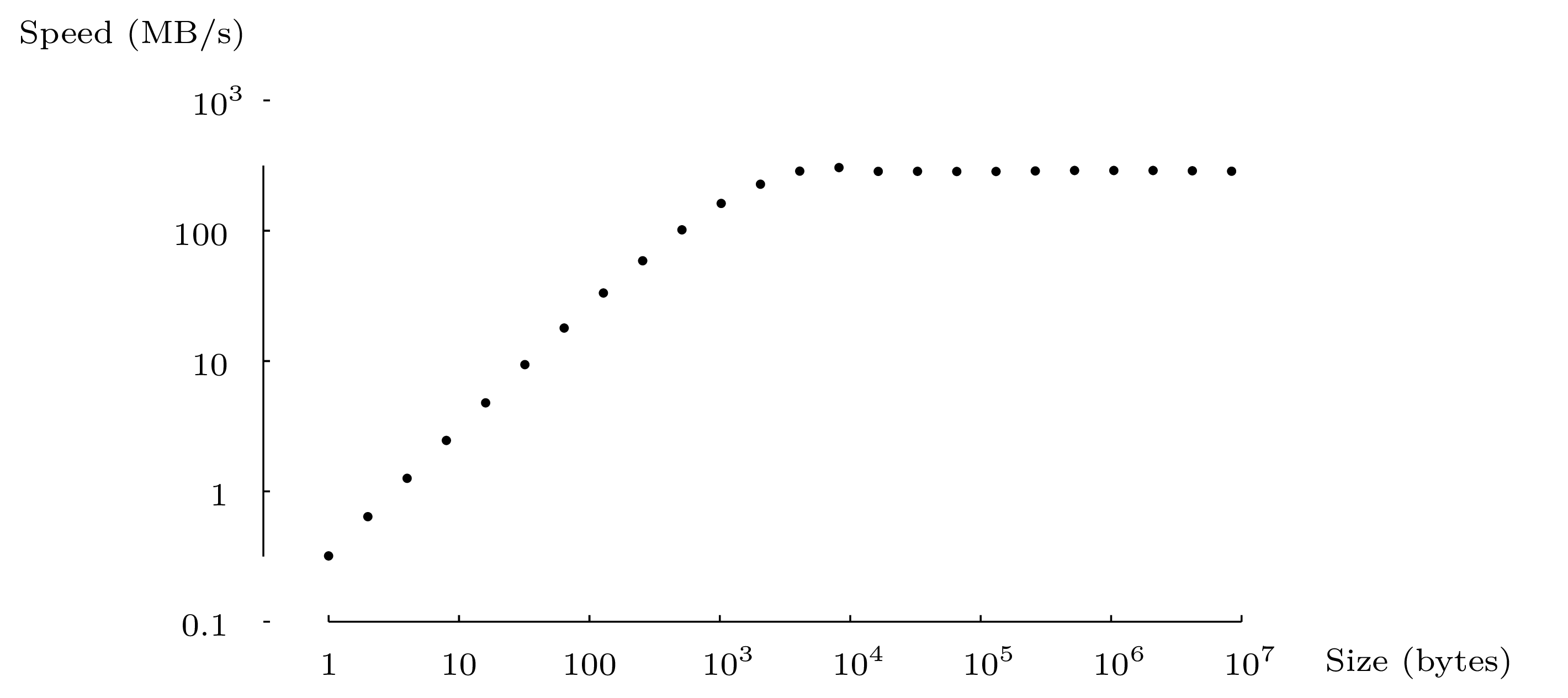
Figure 2 shows the copy speed of file_copy, in
bytes per second, against the size of blocks (the value
buffer_size). The amount of data transferred is the same
regardless of the size of the blocks.
For small block sizes, the copy speed is almost proportional to the
block size. Most of the time is spent not in data transfers but in the
execution of the loop copy_loop and in the calls to read and
write. By profiling more carefully we can see that most of the
time is spent in the calls to read and write. We conclude
that a system call, even if it has not much to do, takes a minimum of
about 4 micro-seconds (on the machine that was used for the test — a
2.8 GHz Pentium 4 ), let us say from 1 to 10 microseconds. For small
input/output blocks, the duration of the system call dominates.
For larger blocks, between 4KB and 1MB, the copy speed is constant and maximal. Here, the time spent in system calls and the loop is small relative to the time spent on the data transfer. Also, the buffer size becomes bigger than the cache sizes used by the system and the time spent by the system to make the transfer dominates the cost of a system call2.
Finally, for very large blocks (8MB and more) the speed is slightly under the maximum. Coming into play here is the time needed to allocate the block and assign memory pages to it as it fills up.
The moral of the story is that, a system call, even if it does very little work, costs dearly — much more than a normal function call: roughly, 2 to 20 microseconds for each system call, depending on the architecture. It is therefore important to minimize the number of system calls. In particular, read and write operations should be made in blocks of reasonable size and not character by character.
In examples like file_copy, it is not difficult to do
input/output with large blocks. But other types of programs are more
naturally written with character by character input or output (e.g.
reading a line from a file, lexical analysis, displaying a number etc.).
To satisfy the needs of these programs, most systems provide
input/output libraries with an additional layer of software between
the application and the operating system. For example, in OCaml the
Pervasives module defines the abstract types
in_channel and
out_channel, similar to file descriptors, and
functions on these types like input_char,
input_line,
output_char, or
output_string. This layer uses buffers to
group sequences of character by character reads or writes into a
single system call to read or write. This results in better
performance for programs that proceed character by character.
Moreover this additional layer makes programs more portable: we just
need to implement this layer with the system calls provided by another
operating system to port all the programs that use this library on
this new platform.
To illustrate the buffered input/output techniques, we implement a fragment
of OCaml Pervasives library. Here is the interface:
We start with the “input” part. The abstract type
in_channel is defined as follows:
The character string of the in_buffer field is, literally, the
buffer. The field in_fd is a (Unix) file descriptor, opened on
the file to read. The field in_pos is the current read position
in the buffer. The field in_end is the number of valid
characters preloaded in the buffer.
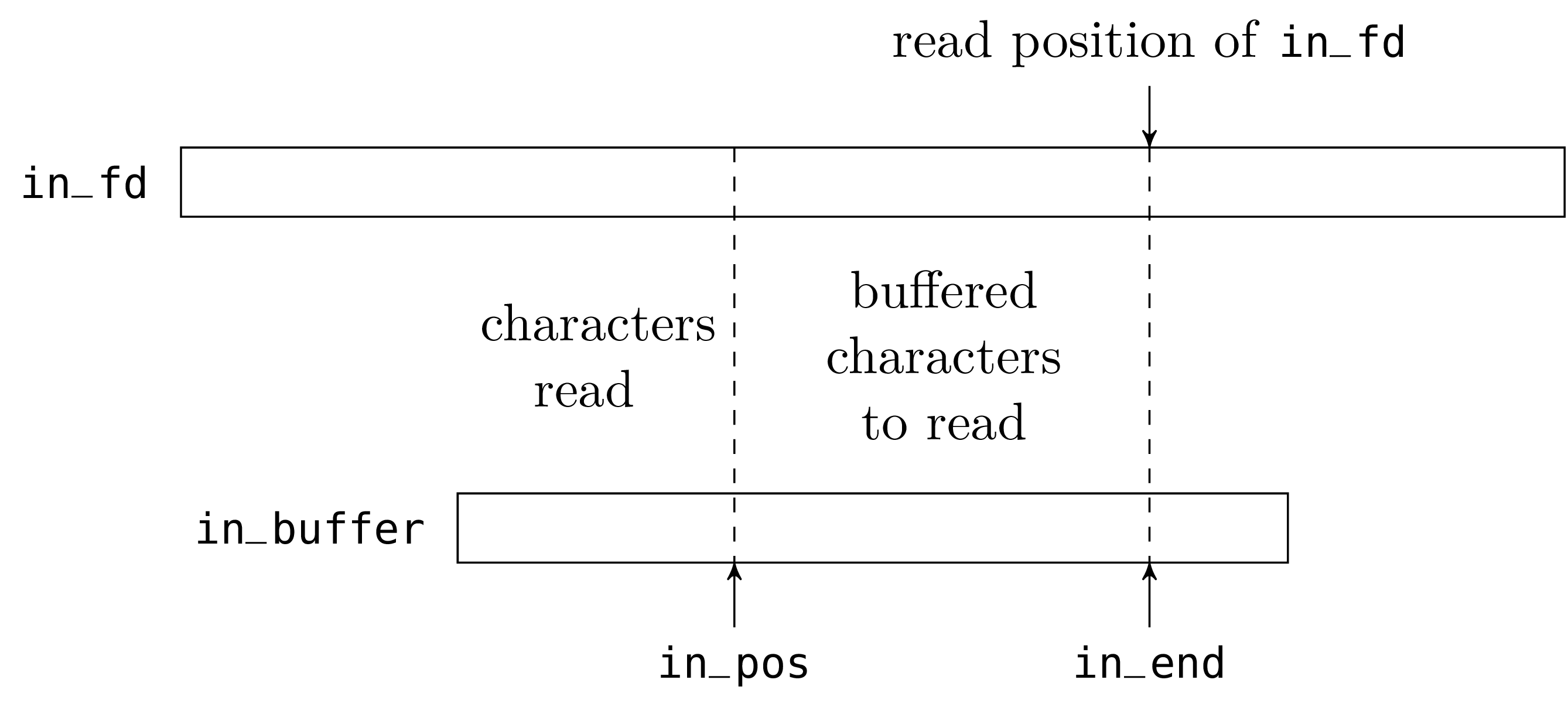
The fields in_pos and in_end will be modified in place during
read operations; we therefore declare them as mutable.
When we open a file for reading, we create a buffer of reasonable size
(large enough so as not to make too many system calls; small enough so
as not to waste memory). We then initialize the field in_fd with
a Unix file descriptor opened in read-only mode on the given file. The
buffer is initially empty (it does not contain any character from the
file); the field in_end is therefore initialized to zero.
To read a character from an in_channel, we do one of two
things. Either there is at least one unread character in the buffer;
that is to say, the field in_pos is less than the field
in_end. We then return this character located at in_pos, and
increment in_pos. Or the buffer is empty and we call read to
refill the buffer. If read returns zero, we have reached the end
of the file and we raise the exception End_of_file. Otherwise, we
put the number of characters read in the field in_end (we may
receive less characters than we requested, thus the buffer may be
only partially refilled) and we return the first character read.
Closing an in_channel just closes the underlying Unix file descriptor.
The “output” part is very similar to the “input” part. The only asymmetry is that the buffer now contains incomplete writes (characters that have already been buffered but not written to the file descriptor), and not reads in advance (characters that have buffered, but not yet read).
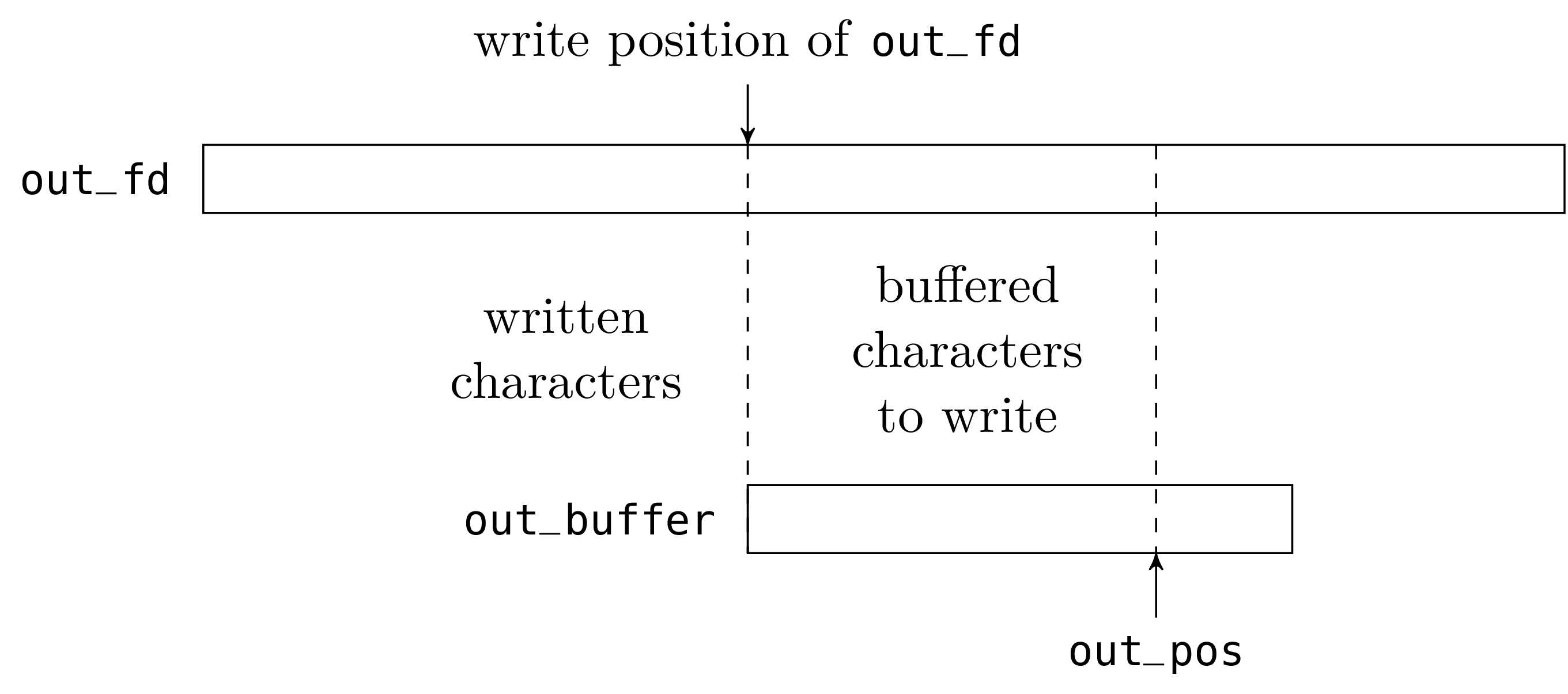
To write a character on an out_channel, we do one of two things.
Either the buffer is not full and we just store the character in the
buffer at the position out_pos and increment that value. Or the
buffer is full and we empty it with a call to write and then
store the character at the beginning of the buffer.
When we close an out_channel, we must not forget to write the
buffer contents (the characters from 0 to out_pos - 1) to the
file otherwise the writes made on the channel since the last time
the buffer was emptied would be lost.
which behaves like a sequence of output_char on each
character of the string, but is more efficient.
Answer.
The system call lseek allows to set the current read/write position of a file descriptor.
The first argument is the file descriptor and the second one the desired position. The latter is interpreted according to the value of the third argument of type seek_command. This enumerated type specifies the kind of position:
SEEK_SET | Absolute position. The second argument specifies the character number to point to. The first character of a file is at position zero. |
SEEK_CUR | Position relative to the current position. The second argument is an offset relative to the current position. A positive value moves forward and a negative value moves backwards. |
SEEK_END | Position relative to the end of file. The
second argument is an offset relative to the end of file.
As for SEEK_CUR, the offset may be positive or negative.
|
The value returned by lseek is the resulting absolute
read/write position.
An error is raised if a negative absolute position is
requested. The requested position can be located after the end
of file. In that case, a read returns zero (end of
file reached) and a write extends the file with zeros until
that position and then writes the supplied data.
To position the cursor on the 1000th character of a file:
To rewind by one character:
To find out the size of a file:
For descriptors opened in O_APPEND mode, the read/write position
is automatically set at the end of the file before each write. Thus
a call lseek is useless to set the write position, it may however
be useful to set the read position.
The behavior of lseek is undefined on certain type of files for
which absolute access is meaningless: communication devices (pipes,
sockets) but also many special files like the terminal.
In most Unix implementations a call to lseek on these files is
simply ignored: the read/write position is set but read/write
operations ignore it. In some implementations, lseek on a pipe or
a socket triggers an error.
The command tail displays the last n lines of a file.
How can it be implemented efficiently on regular files? What can we
do for the other kind of files? How can the option -f be
implemented (cf. man tail)?
Answer.
In Unix, data communication is done via file descriptors representing either permanent files (files, peripherals) or volatile ones (pipes and sockets, see chapters 5 and 6). File descriptors provide a uniform and media-independent interface for data communication. Of course the actual implementation of the operations on a file descriptor depends on the underlying media.
However this uniformity breaks when we need to access all the features provided by a given media. General operations (opening, writing, reading, etc.) remain uniform on most descriptors but even, on certain special files, these may have an ad hoc behavior defined by the kind of peripheral and its parameters. There are also operations that work only with certain kind of media.
We can shorten a normal file with the system calls truncate and ftruncate.
The first argument is the file to truncate and the second the desired size. All the data after this position is lost.
Most operations on files “follow” symbolic links in the sense that they do not apply to the link itself but to the file on which the link points (for example openfile, stat, truncate, opendir, etc.).
The two system calls symlink and readlink operate specifically on symbolic links:
The call symlink f1 f2 creates the file f2 as a symbolic
link to f1 (like the Unix command ln -s f1 f2). The call
readlink returns the content of a symbolic link, i.e. the name of
the file to which the link points.
Special files can be of “character” or “block” type. The former are character streams: we can read or write characters only sequentially. These are the terminals, sound devices, printers, etc. The latter, typically disks, have a permanent medium: characters can be read by blocks and even seeked relative to the current position.
Among the special files, we may distinguish:
/dev/null | This is the black hole which swallows
everything we put into and from which nothing comes out. This is
extremely useful for ignoring the results of a process: we redirect
its output to /dev/null (see chapter 5). |
/dev/tty* | These are the control terminals. |
/dev/pty* | These are the pseudo-terminals: they are not real terminals but simulate them (they provide the same interface). |
/dev/hd* | These are the disks. |
/proc | Under Linux, system parameters organized as a file system. They allow reads and writes. |
The usual file system calls on special files can behave differently.
However, most special files (terminals, tape drives, disks, etc.)
respond to read and write in the obvious manner (but
sometimes with restrictions on the number of bytes written or read),
but many ignore lseek.
In addition to the usual file system calls, special files which represent peripherals must be commanded and/or configured dynamically. For example, for a tape drive, rewind or fast forward the tape; for a terminal, choice of the line editing mode, behavior of special characters, serial connection parameters (speed, parity, etc.). These operations are made in Unix with the system call ioctl which group together all the particular cases. However, this system call is not provided by OCaml; it is ill-defined and cannot be treated in a uniform way.
Terminals and pseudo-terminals are special files of type character which can be configured from OCaml. The system call tcgetattr takes a file descriptor open on a special file and returns a structure of type terminal_io which describes the status of the terminal according to the posix standard.
This structure can be modified and given to the function tcsetattr to change the attributes of the peripheral.
The first argument is the file descriptor of the peripheral. The last
argument is a structure of type terminal_io describing the
parameters of the peripheral as we want them. The second argument is a
value of the enumerated type setattr_when that
indicates when the change must be done: immediately (TCSANOW),
after having transmitted all written data (TCSADRAIN) or after
having read all the received data (TCAFLUSH). TCSADRAIN is
recommended for changing write parameters and TCSAFLUSH for read
parameters.
When a password is read, characters entered by the user should not be echoed if the standard input is connected to a terminal or a pseudo-terminal.
The read_passwd function starts by getting the current settings
of the terminal connected to stdin. Then it defines a modified
version of these in which characters are not echoed. If this fails the
standard input is not a control terminal and we just read a
line. Otherwise we display a message, change the terminal settings, read the
password and put the terminal back in its initial state. Care must be
taken to set the terminal back to its initial state even after a read
failure.
Sometimes a program needs to start another and connect its standard input
to a terminal (or pseudo-terminal). OCaml does not provide any
support for this3. To achieve that, we must manually look among the
pseudo-terminals (in general, they are files with names in the form of
/dev/tty[a-z][a-f0-9]) and find one that is not already open. We
can then open this file and start the program with this file on its
standard input.
Four other functions control the stream of data of a terminal (flush waiting data, wait for the end of transmission and restart communication).
The function tcsendbreak sends an interrupt to the
peripheral. The second argument is the duration of the interrupt
(0 is interpreted as the default value for the
peripheral).
The function tcdrain waits for all written data to be transmitted.
Depending on the value of the second argument, a call to the
function tcflush discards the data written but not yet
transmitted (TCIFLUSH), or the data received but not yet read
(TCOFLUSH) or both (TCIOFLUSH).
Depending on the value of the second argument, a call to the
function tcflow suspends the data transmission
(TCOOFF), restarts the transmission (TCOON), sends a control
character stop or start to request the
transmission to be suspended (TCIOFF) or restarted (TCION).
The function setsid puts the process in a new session and detaches it from the terminal.
Two processes can modify the same file in parallel; however, their
writes may collide and result in inconsistent data. In some cases data
is always written at the end and opening the file with O_APPEND
prevents this. This is fine for log files but it does not
work for files that store, for example, a database because writes are
performed at arbitrary positions. In that case processes using the
file must collaborate in order not to step on each others toes. A
lock on the whole file can be implemented with an auxiliary file (see
page ??) but the system call lockf allows
for finer synchronization patterns by locking only parts of a file.
We extend the function file_copy (section 2.9) to
support symbolic links and directories in addition to normal files.
For directories, we recursively copy their contents.
To copy normal files we reuse the function file_copy we already
defined.
The function set_infos below modifies the owner, the
access rights and the last dates of access/modification
of a file. We use it to preserve this information for copied files.
The system call utime modifies the dates of access and
modification. We use chmod and chown to re-establish
the access rights and the owner. For normal users, there are
a certain number of cases where chown will fail with a
“permission denied” error. We catch this error and ignore it.
Here’s the main recursive function.
We begin by reading the information of the source file. If it is
a normal file, we copy its contents with file_copy and its
information with set_infos. If it is a symbolic link, we read
where it points to and create a link pointing to the same object. If
it is a directory, we create a destination directory, then we read the
directory’s entries (ignoring the entries about the directory itself
or its parent) and recursively call copy_rec for each entry. All
other file types are ignored, with a warning.
The main program is straightforward:
Copy hard links cleverly. As written above copy_rec creates n
duplicates of the same file whenever a file occurs under n different
names in the hierarchy to copy. Try to detect this situation, copy
the file only once and make hard links in the destination hierarchy.
Answer.
The tar file format (for tape archive) can store a file
hierarchy into a single file. It can be seen as a mini file system.
In this section we define functions to read and write tar
files. We also program a command readtar such that readtar a
displays the name of the files contained in the archive a and
readtar a f extracts the contents of the file f contained in
a. Extracting the whole file hierarchy of an archive and
generating an archive for a file hierarchy is left as an exercise.
A tar archive is a set of records. Each record represents a
file; it starts with a header which encodes the information
about the file (its name, type, size, owners, etc.) and is followed by
the contents of the file. The header is a block of 512 bytes structured as
shown in table 3.
| Offset | Length | Code Type | Name | Description |
| 0 | 100 | string | name | File name |
| 100 | 8 | octal | perm | File permissions |
| 108 | 8 | octal | uid | Id of user owner |
| 116 | 8 | octal | gid | Id of group owner |
| 124 | 12 | octal | size | File size (in bytes) |
| 136 | 12 | octal | mtime | Date of last modification |
| 148 | 8 | octal | checksum | Header checksum |
| 156 | 1 | character | kind | File type |
| 157 | 100 | octal | link | Link |
| 257 | 8 | string | magic | Signature ("ustar\032\032\0") |
| 265 | 32 | string | user | Name of user owner |
| 297 | 32 | string | group | Name of group owner |
| 329 | 8 | octal | major | Peripheral major number |
| 337 | 8 | octal | minor | Peripheral minor number |
| 345 | 167 | Padding | ||
'\000'; except the fields kind and
size in which '\000' optional.
The file contents is stored right after the header, its size is rounded to a multiple of 512 bytes (the extra space is filled with zeros). Records are stored one after the other. If needed, the file is padded with empty blocks to reach at least 20 blocks.
Since tar archives are also designed to be written on brittle media
and reread many years later, the header contains a checksum
field which allows to detect when the header is damaged. Its value is
the sum of all the bytes of the header (to compute that sum we assume
that the checksum field itself is made of zeros).
The kind header field encodes the file type in a byte as follows4:
'\0' or '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' |
REG | LINK | LNK | CHR | BLK | DIR | FIFO | CONT
|
Most of the cases correspond to the values of the Unix file type
file_kind stored in the st_kind field of the
stats structure. LINK is for hard links which
must lead to another file already stored within the archive. CONT
is for ordinary file, but stored in a contiguous area of memory (this
is a feature of some file systems, we can treat it like an ordinary
file).
The link header field stores the link when kind is LNK
or LINK. The fields major and minor contain the major
and minor numbers of the peripheral when kind is CHR or
BLK. These three fields are not used in other cases.
The value of the kind field is naturally represented by a
variant type and the header by a record:
Reading a header is not very interesting, but it cannot be ignored.
An archive ends either at the end of file where a new record would
start or on a complete, but empty, block. To read a header we thus try
to read a block which must be either empty or complete. For that we
reuse the really_read function defined earlier. The end of file
should not be reached when we try to read a block.
To perform an operation in an archive, we need to read the records sequentially until we find the target of the operation. Usually we just need to read the header of each record without its contents but sometimes we also need to get back to a previous one to read its contents. As such we keep, for each record, its header and its location in the archive:
We define a general iterator that reads and accumulates the records
of an archive (without their contents). To remain general, the
accumulating function f is abstracted. This allows to use the
same iterator function to display records, destroy them, etc.
The function fold_aux starts from a position offset with a
partial result accu. It moves to offset where a record
should start, reads a header, constructs the record r and starts
again at the end of the record with the new (less partial) result
f r accu. It stops when there’s no header: the end of the archive
was reached.
We just display the name of records without keeping them:
The command readtar a f must look for the file f in the
archive and, if it is a regular file, display its contents. If f
is a hard link on g in the archive, we follow the link and
display g since even though f and g are represented
differently in the archive they represent the same file. The fact that
g or f is a link on the other or vice versa depends only on
the order in which the files were traversed when the archive was
created. For now we do not follow symbol links.
Hard link resolution is done by the following mutually recursive functions:
The function find_regular finds the regular file corresponding to
the record r. If r is a regular file itself, r is
returned. If r is a hard link the function looks for the regular
file in the archive’s previous records stored in list with the
function find_file. In all other cases, the function aborts.
Once the record is found we just need to display its contents. After
positioning the descriptor at the start of the record’s contents this
operation is very similar to the file_copy example.
We now just need to combine these functions correctly.
We read the records in the archive (but not their contents) until we
find the record with the target name. We then call the function
find_regular to find the record that actually contains the file.
This second, backward, search must succeed if the archive is
well-formed. The first search may however fail if the target name is
not in the archive. In case of failure, the program takes care to
distinguish between these two cases.
Here is the main function which implements the command readtar:
Extend the command readtar so that it follows symbolic links in
the sense that if the link points to a file of the archive that file’s
contents should be extracted.
Answer.
Write a command untar such that untar a extracts and creates
all the files in the archive a (except special files)
restoring if possible the information about the files
(owners, permissions) as found in the archive.
The file hierarchy should be reconstructed in the current working
directory of the untar command. If the archive tries to create
files outside a sub-directory of the current working directory this
should be detected and prohibited. Nonexistent directories not explicitly
mentioned in the archive should be created with the user’s default
permissions.
Answer.
Write a program tar such that tar -xvf a f1 f2 ...
constructs the archive a containing the list of files f1,
f2, etc. and their sub-directories.
Answer.
O_CREAT of open correctly.write
system calls to make the complete transfer — see the discussion in
section 5.7. But this limit is bigger than the
size of system caches and it is not observable.tar format.