


So far, we have learned how to manage processes and how they can communicate with the environment by using files. In the remainder of the course we see how processes running in parallel can cooperate by communicating among themselves.
Regular files are not a satisfactory communication medium for processes
running in parallel. Take for example a reader/writer situation in
which one process writes data and the other reads them. If a file is used
as the communication medium, the reader can detect that the file
does not grow any more (read returns zero), but it does not know
whether the writer is finished or simply busy computing
more data. Moreover, the file keeps track of all the data transmitted,
requiring needless disk space.
Pipes provide a mechanism suitable for this kind of communication. A pipe is made of two file descriptors. The first one represents the pipe’s output. The second one represents the pipe’s input. Pipes are created by the system call pipe:
The call returns a pair (fd_in, fd_out) where fd_in is a
file descriptor open in read mode on the pipe’s output and
fd_out is file descriptor open in write mode on the pipe’s
input. The pipe itself is an internal object of the kernel that can
only be accessed via these two descriptors. In particular, it has no
name in the file system.

A pipe behaves like a queue (first-in, first-out). The first
thing written to the pipe is the first thing read from the pipe.
Writes (calls to write on the pipe’s input
descriptor) fill the pipe and block when the pipe is full. They block
until another process reads enough data at the other end of the pipe
and return when all the data given to write have been
transmitted. Reads (calls to read on the pipe’s output
descriptor) drain the pipe. If the pipe is empty, a call to read
blocks until at least a byte is written at the other end. It then
returns immediately without waiting for the number of bytes requested
by read to be available.
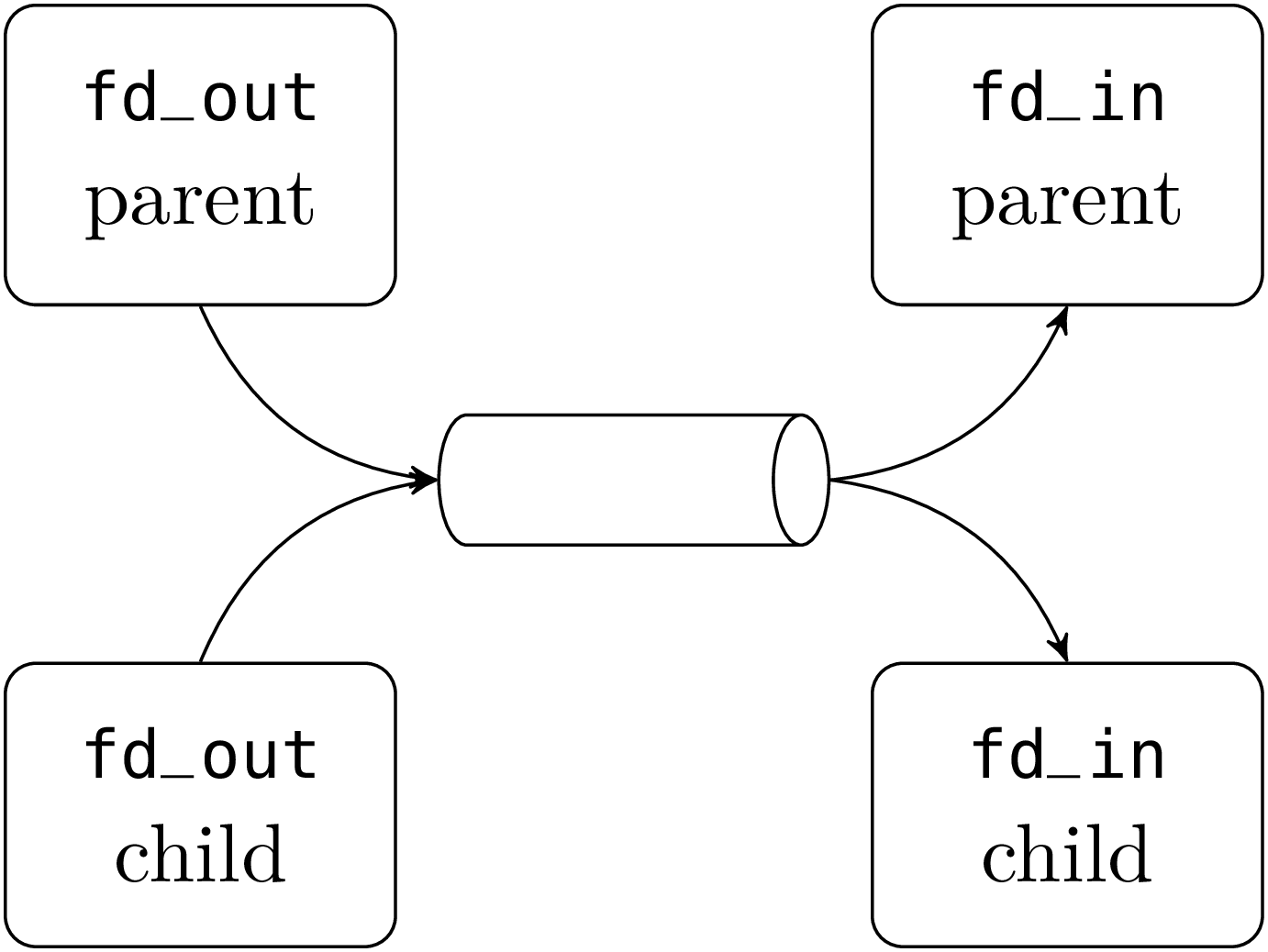
Pipes are useless if they are written and read by the same process (such a process will likely block forever on a substantial write or on a read on the empty pipe). Hence they are usually read and written by different processes. Since a pipe has no name, one of these processes must be created by forking the process that created the pipe. Indeed, the two file descriptors of the pipe, like any other file descriptors, are duplicated by the call to fork and thus refer to the same pipe in the parent and the child process.
The following snippet of code is typical.
After the fork there are two descriptors open on the pipe’s
input, one in the parent and the other in the child. The same
holds for the pipe’s output.
In this example the child becomes the writer and the parent the
reader. Consequently the child closes its descriptor fd_in on the
pipe’s output (to save descriptors and to avoid programming
errors). This leaves the descriptor fd_in of the parent unchanged
as descriptors are allocated in process memory and after the fork the
parent’s and child’s memory are disjoint. The pipe, allocated in system
memory, still lives as there’s still the descriptor fd_in of the
parent open in read mode on the pipe’s output. Following the same
reasoning the parent closes its descriptor on the pipe’s input. The
result is as follows:
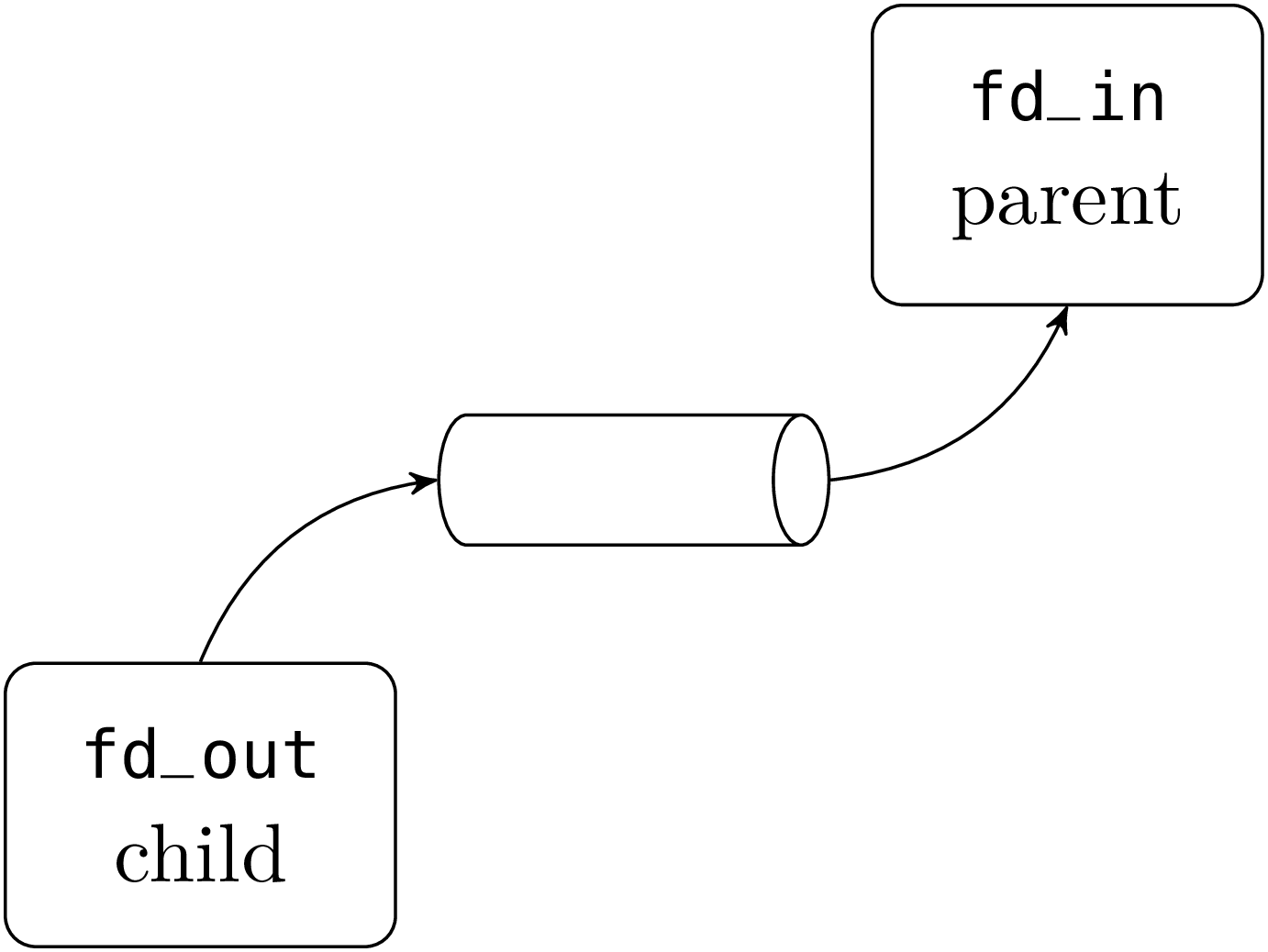
Data written by the child on fd_out is transmitted to fd_in
in
the parent.
When all the descriptors on a pipe’s input are closed and the pipe is
empty, a call to read on its output returns zero:
end of file. And when all the descriptors on a pipe’s output are
closed, a call to write on its input kills the writing
process. More precisely the kernel sends the signal sigpipe to
the process calling write and the default handler of this signal
terminates the process. If the signal handler of sigpipe is
changed, the call to write fails with an EPIPE error.
This is a classic example of parallel programming. The task of the program is to enumerate the prime numbers and display them interactively as they are found. The idea of the algorithm is as follows. A process enumerates on its output the integers from 2 onwards. We connect this process to a “filter” process that reads an integer p on its input and displays it.
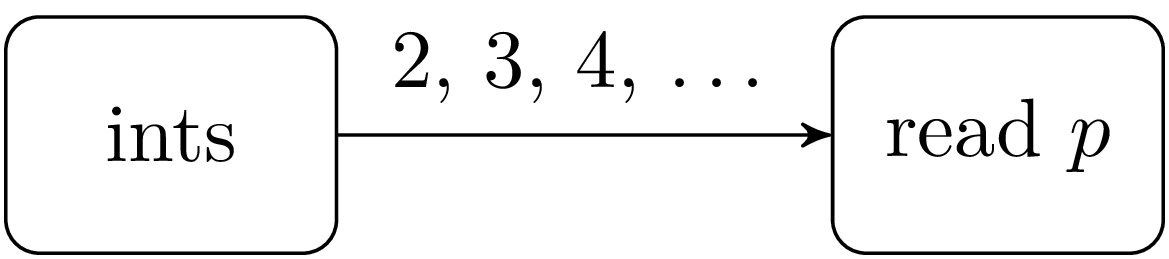
Therefore, the first filter process reads p=2. Then it creates a new filter process connected to its output and filters out the multiples of p it gets on its input; all numbers it reads that are not a multiple of p are rewritten on its output.

Hence the next process reads p=3, which it displays and then starts to filter multiples of 3, and so on.
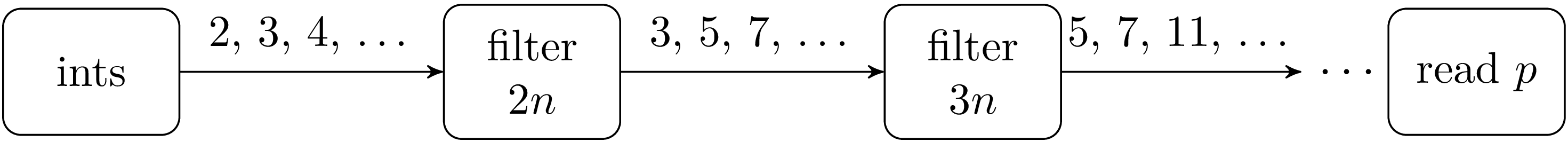
This algorithm cannot be directly implemented in Unix because it creates too many processes (the number of primes already found plus one). Most Unix systems limit the number of process to a few dozens. Moreover, on a uniprocessor machine, too many processes active simultaneously can bring the system to its knees because of the high costs incurred by switching process contexts. In the following implementation each process first reads n primes p1, …, pn on its input before transforming itself in a filter that eliminate the multiples of p1, …, pn. In practice n = 1000 gives a reasonable slowdown on process creation.
We start with the process that enumerates integers from 2 to k.
To output and input the integers, the following functions are used:
The function output_binary_int from the standard library writes a
four-byte binary representation of an integer on an
out_channel. The integer can be read back by the function
input_binary_int on an in_channel. Using these functions
from the standard library has two advantages: first, there is no need to
code the function converting integers to a bytewise
representation1; second, since
these functions use buffered i/o, fewer system calls are
performed, which results in better performance. The following functions
create an in_channel or out_channel to buffer the
i/o on the given descriptor:
They allow a program to perform buffered i/o on descriptors acquired
indirectly or that are not the result of opening a file. These
functions are not here to mix buffered i/o with non-buffered
i/o; this is possible but very brittle and highly
discouraged — particularly for input. Note also that it is possible
but very risky to create more than one in_channel (for example)
on the same descriptor.
We now continue with the filter process. It uses the auxiliary function
read_first_primes. A call to read_first_primes input count
reads count prime numbers on input (an in_channel) and eliminates
multiples of the primes already read. These count primes are
displayed as soon as they are read and we return them in a list.
And here is the concrete filter function:
The filter starts by calling read_first_primes to read the first
1000 prime numbers on its input (the input argument of type
in_channel). Then we create a pipe and clone the process with
fork. The child starts to filter the output of this pipe. The
parent reads numbers on its input and writes each one to the pipe if it
is not a multiple of one of the 1000 primes it initially read.
Finally, the main program just connects the integer generator to the
first filter process with a pipe. Invoking the program sieve k
enumerates the primes smaller than k. If k is omitted (or
not an integer), it defaults to max_int.
In this example we do not wait for the child before stopping the parent. The reason is that parent processes are generators for their children.
When k is given, the parent will terminate first and close
the descriptor on the input of the pipe connected to its child. Since
OCaml empties the buffers of descriptors open in write mode when a
process stops, the child process will read the last integer provided
by the parent. After that the child also stops etc. Thus, in this
program children become orphaned and are temporarily attached to the
process init before they die in turn.
If k is not given, all processes continue indefinitely until one or
more are killed. The death of a process results in the death of its child
as described above. It also closes the output of the pipe connected to
its parent. This will in turn kill the parent at the next write on the
pipe (the parent will receive a sigpipe signal whose default
handler terminates the process).
What needs to be changed so that the parent waits on the termination of its children? Answer.
Whenever a prime is found, the function print_prime evaluates
print_newline (). This performs a system call to empty the standard
output buffer and artificially limits the execution speed of the program.
In fact print_newline () executes print_char '\n'
followed by flush Pervasives.stdout. What can happen if
print_newline () is replaced by print_char '\n'? What needs
to be added to solve the problem?
Answer.
On some Unix systems (System V, SunOS, Ultrix, Linux, bsd) pipes with a name in the file system can be created. These named pipes (also known as fifo) allow processes to communicate even if they are not in a parent/child relationship. This contrasts with regular pipes that limit communication between the pipe creator and its descendants.
The system call mkfifo creates a named pipe:
The first argument is the name of the pipe, and the second one represents the requested access permissions.
Named pipes are opened with a call to openfile like any
regular file. Reads and writes on a named pipe have the same semantics
as those on regular ones. Opening a named pipe in read-only mode
(resp. write-only mode) blocks until the pipe is opened by another
process for writing (resp. reading); if this has already happened,
there’s no blocking. Blocking can be avoided altogether by opening the
pipe with the flag O_NONBLOCK, but in this case reads and writes
on the pipe won’t block either. After the
pipe is opened, the function clear_nonblock will change this flag to make further
reads or writes on the pipe blocking. Alternatively,
set_nonblock will make reads and writes non-blocking.
So far, we still do not know how to connect the standard input and
output of processes with a pipe as the shell does to execute
commands like cmd1 | cmd2. Indeed, the descriptors we get on the
ends of a pipe with a call to pipe (or to openfile on a
named pipe) are new descriptors, distinct from stdin,
stdout or stderr.
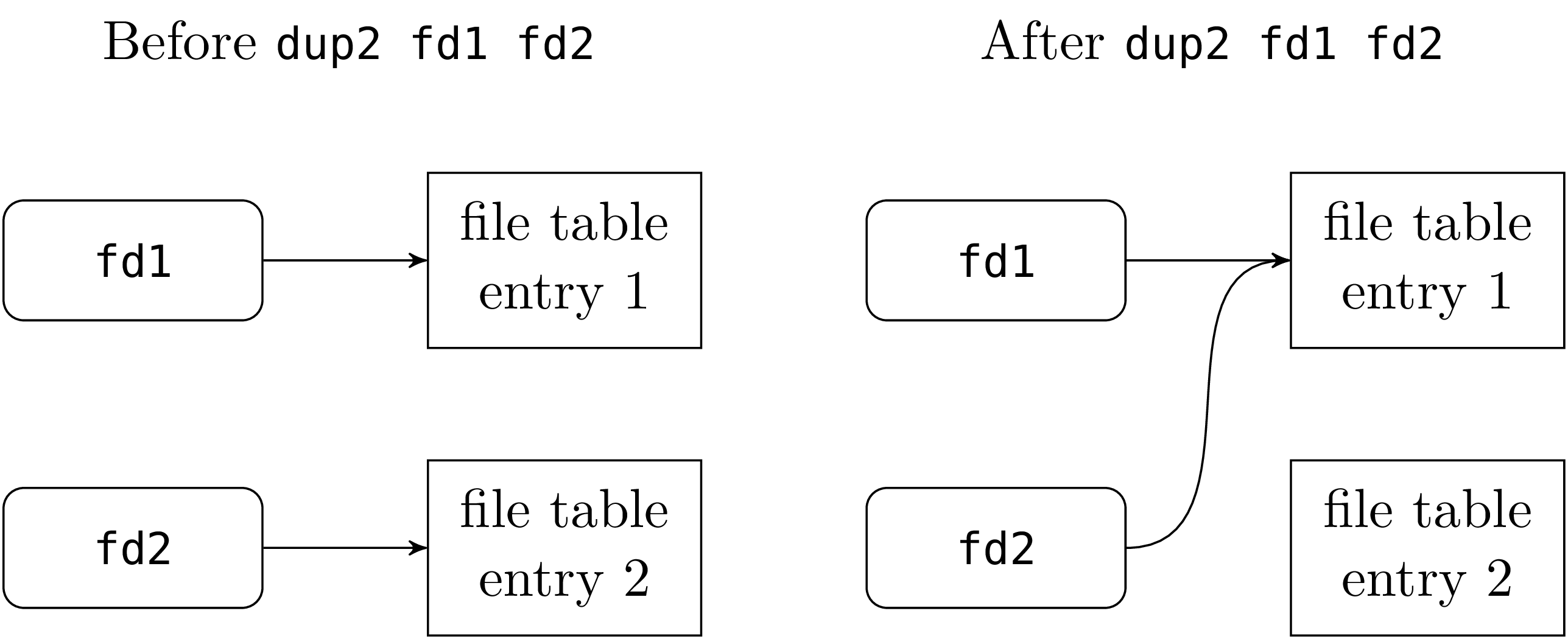
To address this problem, Unix provides the system call dup2 (read: “duplicate a descriptor to another descriptor”) that gives one file descriptor another one’s meaning. This can be done because there is a level of indirection between a file descriptor (an object of type file_descr) and the object in the kernel called a file table entry that points to the actual file or pipe and maintains its current read/write position.
The effect of dup2 fd1 fd2 is to update the descriptor fd2 to refer to
the file table entry pointed to by fd1. After the call, these two
descriptors refer to same file or pipe, at the same read/write
position.
Standard input redirection.
After the call to dup2, the descriptor stdin points to the
file foo. Any read on stdin will read from the file foo
(so does any read on fd; but since we won’t use it, we close it
immediately). This setting on stdin is preserved by execvp
and the program bar will execute with its standard input
connected to the file foo. This is the way the shell executes
commands like bar < foo.
Standard output redirection.
After the call to dup2, the descriptor stdout points to
the file foo. Any write on stdout will write to the file
foo (so does any write on fd; but since we won’t use it we
close it immediately). This setting on stdout is preserved by
execvp and the program bar will execute with its standard output
connected to the file foo. This is the way the shell executes
commands like bar > foo.
Connecting the output of a program to the input of another.
The program cmd2 is executed with its standard input connected to
the output of the pipe. In parallel, the program cmd1 is executed
with its standard output connected to the input of the pipe. Therefore
whatever cmd1 writes on its standard output is read by cmd2
on its standard input.
What happens if cmd1 terminates before cmd2? When cmd1
terminates, all its open descriptors are closed. This means that there’s no
open descriptor on the input of the pipe. When cmd2 has read all
the data waiting in the pipe, the next read returns an end of file;
cmd2 will then do what it is assigned to do when it reaches the
end of its standard input — for example, terminate.
Now, if cmd2 terminates before cmd1, the last descriptor on
the output of the pipe is closed and cmd1 will get
a signal (which by default kills the process) the next time
it tries to write on its standard output.
Implement some of the other redirections provided by the shell
sh. Namely:
Swapping two descriptors requires care. The naive sequence
dup2 fd1 fd2; dup2 fd2 fd1 does not work. Indeed, the second
redirection has no effect since after the first one both descriptors
fd1 and fd2 already point to the same file table entry. The
initial value pointed by fd2 was lost. This is like swapping the
contents of two reference cells: a temporary variable is needed to
save one of the two values. Here we can save one of the
descriptors by copying it with the system call dup.
The call to dup fd returns a new descriptor pointing on the same
file table entry as fd. For example we can swap stdout and
stderr with:
After the swap, do not forget to close the temporary descriptor
tmp to prevent a descriptor leak.
We program a command compose such that
behaves like the shell command:
The bulk of the work is done by the for loop starting at
line 6. For each command except the last one, we
create a new pipe and a child process. The child connects the pipe’s
input to its standard output and executes the command. After the
fork it inherits the standard input of its parent. The main
process (the parent) connects the pipe’s output to its standard input
and continues the loop. Suppose (induction hypothesis) that at the
beginning of the ith iteration, the situation is as follows:
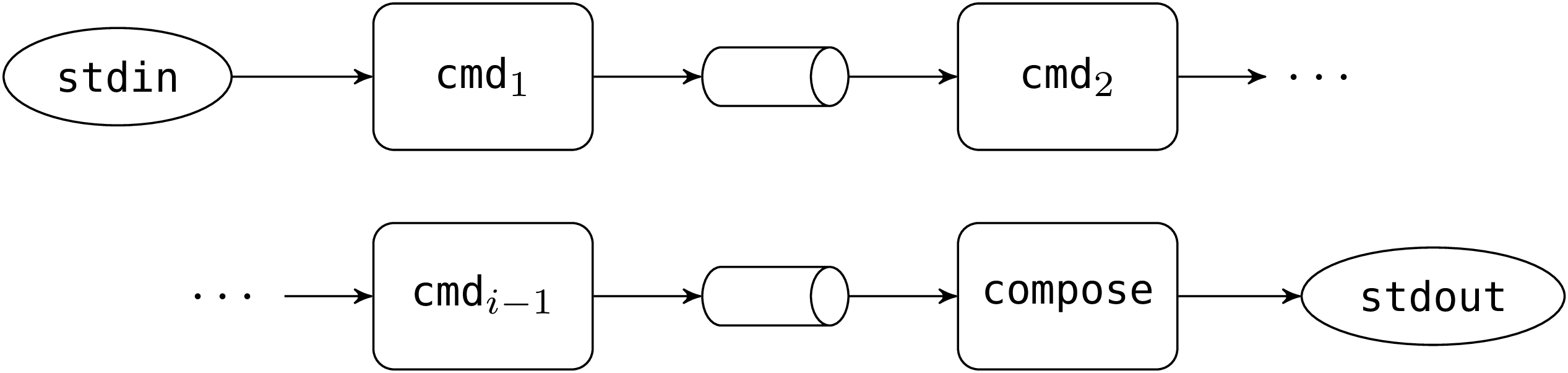
Rounded boxes represent processes. Their standard input is on the
left, their standard output on the right. The ellipses represent
the initial standard input and output of the compose process.
Just after the call to pipe and fork we have:

When the parent calls dup2, we get:

When the child calls dup2 and execv, we get:

and everything is ready for the next iteration.
The last command is forked after the loop because there’s no need to
create a new pipe: the process compose already has the right
standard input (the output of the next to last command) and output
(the one initially given to the command compose) for the
child. Hence it is sufficient to fork and exec. The parent then
waits for its children to terminate: it calls wait repeatedly
until the error ECHILD (no child to wait for) is raised. The
children’s return codes are combined with a bitwise “or”
(lor operator) to create a meaningful return code for
compose : zero if all the children returned zero, different from
zero otherwise.
Note that we execute commands through the shell /bin/sh. This
prevents us from having to parse complex commands into tokens as
in the following invocation:
Adding this functionality to our program would complicate it needlessly.
In all the examples so far, processes communicate linearly: each process reads data coming from at most one other process. In this section we highlight and solve the problems occurring whenever a process needs to read data coming from many processes.
Consider the example of a multi-windowed terminal emulator. Suppose we have a computer, called the client, connected to a Unix machine by a serial port. We want to emulate, on the client, many terminal windows connected to different user processes on the Unix machine. For example, one window can be connected to a shell and another to a text editor. Outputs from the shell are displayed in the first window and those from the editor in the other. If the first window is active, keystrokes from the client’s keyboard are sent to the input of the shell and if the second window is active they are sent to the input of the editor.
Since there’s only a single physical link between the client and the Unix machine, we need to multiplex the virtual connections between windows and processes by interleaving the data transmissions. Here’s the protocol we are going to use. On the serial port, we send messages with the following structure:
On the Unix machine, user processes (shell, editor, etc.) are
connected by a pipe to one or more auxiliary processes that read and
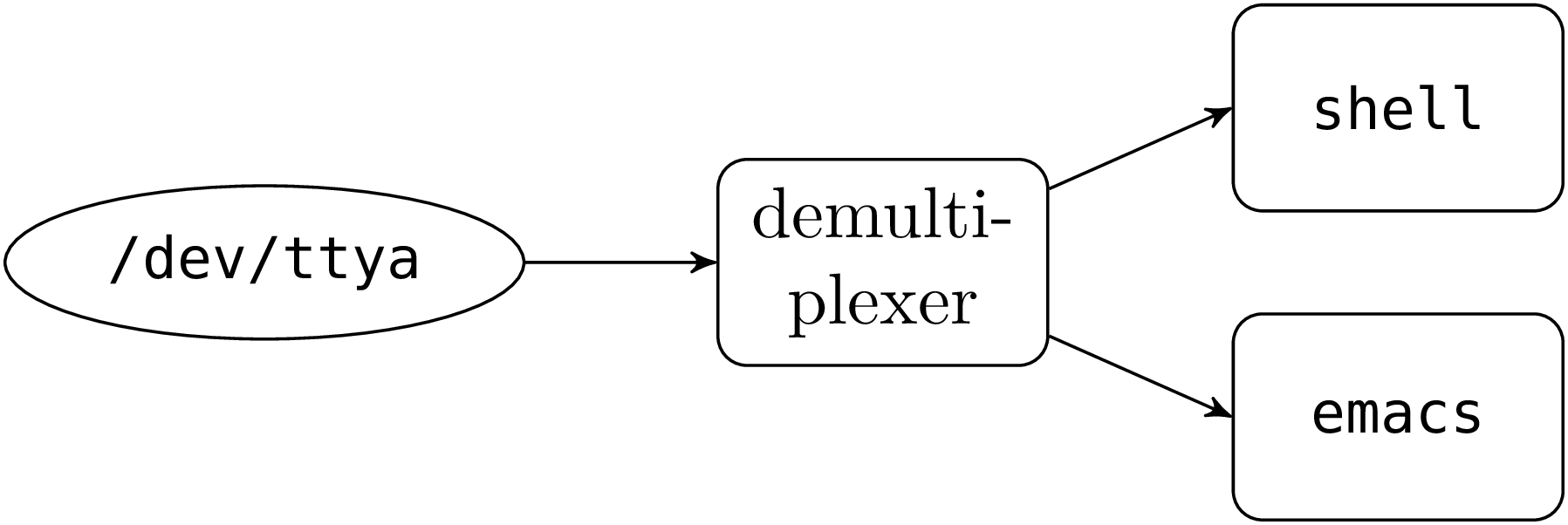
write on the serial port and (de)multiplex the data. The serial port
is a special file (/dev/ttya, for example), on which the
auxiliary processes read and write to communicate with the
client.
Demultiplexing (transmission from the client to the user processes) does not pose any particular problem. We just need a process that reads messages on the serial port and writes the extracted data on the pipe connected to the standard input of the receiving user process.
Multiplexing (transmission from user processes to the client) is more tricky. Let us try to mimic the demultiplexer: a process reads sequentially the output of the pipes connected to the standard output of the user processes and then writes the data it reads as message on the serial port by adding the receiving window number and the length of the data.

This does not work, because reading a pipe can block. For example, if we try to read the output of the shell but it has nothing to display at that moment, the multiplexer process will block, and waiting characters from the editor will be ignored. There’s no way to know in advance on which pipes there is data waiting to be displayed (in parallel algorithms, the situation where a process is perpetually denied access to a shared resource is called starvation).
Here is another approach: we associate with each user process a
repeater process. The repeater reads the output of the pipe
connected to the standard output of the user process, transforms the
data into messages and writes the result directly on the serial port
(each repeater process opens /dev/ttya in write mode).

Since each user process has its output transmitted independently,
blocking problems are solved. However the protocol may not be
respected. Two repeaters may try to write a message at the same time
and the Unix kernel does not guarantee the atomicity of writes, i.e.
that they are performed in a single uninterruptible operation.
Thus the kernel may choose to write only a part of a message from a
repeater to /dev/ttya, then write a full message from another
repeater and finally write the remaining part of the first message.
This will utterly confuse the demultiplexer on the client:
it will interpret the second message as part of the data of the
first and then interpret the rest of the data as a new message header.
To avoid this, repeater processes must synchronize so that at anytime
at most one of them is writing on the serial port (in parallel
algorithms we say that we need to enforce the mutual exclusion of
repeaters on the access to the serial link). Technically, this can be
done with concepts we have already seen so far: repeaters can create a
specific file (the “lock”) with the O_EXCL flag before
sending a message and destroy it after they are done writing to the
serial port. However this technique is not very efficient because the
lock creation and destruction costs are too high.
A better solution is to take the first approach (a single
multiplexer process) and set the output of the pipes connected to the
standard output of user processes in non-blocking mode with
set_nonblock. A read on an empty pipe will not block but return
immediately by raising the error EAGAIN or EWOULDBLOCK. We
just ignore this error and try to read the output of the next user
process. This will prevent starvation and avoid any mutual exclusion
problem. However it is a very inefficient solution, the multiplexer
process performs what is called “busy waiting”: it uses
processing time even if no process is
sending data. This can be alleviated by introducing calls to
sleep in the reading loop; unfortunately, it is very difficult to find
the right frequency. Short sleeps cause needless processor load when there
is little data, and long sleeps introduce perceptible delays when there is a lot of data.
This is a serious problem. To solve it, the designers of bsd
Unix introduced a new system call, select, which is now
available on most Unix variants. A call to select allows a
process to wait (passively) on one or more input/output events.
An event can be:
The system call select has the following signature:
The first three arguments are sets of descriptors represented by
lists: the first argument is the set of descriptors to watch for read
events; the second argument is the set of descriptors to watch for
write events; the third argument is the set of descriptors to watch
for exceptional events. The fourth argument is a timeout in
seconds. If it is positive or zero, the call to select will return
after that time, even if no event occurred. If it is negative, the call
to select waits indefinitely until one of the requested events occurs.
The select call returns a triplet of descriptor lists: the first
component is the list of descriptors ready for reading, the second
component those ready for writing and the third one those on which an
exceptional condition occurred. If the timeout expires before any
event occurs, the three lists are empty.
The code below watches read events on the descriptors fd1 and
fd2 and returns after 0.5 seconds.
The following multiplex function is central to the
multiplexer/demultiplexer of the multi-windowed terminal emulator
described above.
To simplify, the multiplexer just sets the receiver of messages according to their provenance and the demultiplexer redirects data directly to the receiver number. In other words, we assume that either each sender talks to a receiver with the same number, or that the correspondence between them is magically established in the middle of the serial link by rewriting the receiver number.
The multiplex function takes a descriptor open on the serial port
and two arrays of descriptors of the same size, one containing pipes
connected to the standard input of the user processes, the other
containing pipes connected to their standard output.
The multiplex function starts by constructing a set of
descriptors (input_fds) that contain the input descriptors
(those connected to the standard output of the user processes) and the
descriptor of the serial port. On each iteration of the
while loop we call select to watch for pending reads in
input_fds. We do not watch for any write or exceptional event and
we do not limit the waiting time. When select returns, we test whether
there is data waiting on an input descriptor or on the serial port.
If there is data on an input descriptor we read this input into a
buffer, add a message header and write the result on the serial
port. If read returns zero this indicates that the corresponding
pipe was closed. The terminal emulator on the client will receive a
message with zero bytes, signaling that the user process
with that number died; it can then close the corresponding window.
If there is data on the serial port, we read the two-byte message
header which gives us the number i of the receiver and the number
n of bytes to read. We then read n bytes on the channel and
write them on the output i connected to the standard input of the
corresponding user process. However, if n is 0, we close the
output i. The idea is that the terminal emulator at the other end
sends a message with n = 0 to indicate an end of file on the
standard input of the receiving user process.
We get out of the loop when really_read raises the exception
End_of_file, which indicates an end of file on the
serial port.
The function write of the Unix module iterates the system call
write until all the requested bytes are effectively written.
However, when the descriptor is a pipe (or a socket, see
chapter 6), writes may block and the system call
write may be interrupted by a signal. In this case the OCaml
call to Unix.write is interrupted and the error EINTR is
raised. The problem is that some of the data may already have been
written by a previous system call to write but the actual size
that was transferred is unknown and lost. This renders the function
write of the Unix module useless in the presence of signals.
To address this problem, the Unix module also provides the
“raw” system call write under the name
single_write.
With single_write, if an error is raised it is guaranteed that no
data is written.
The rest of this section shows how to implement this
function. Fundamentally, it is just a matter of interfacing OCaml with
C (more information about this topic can be found in the relevant
section of the OCaml manual). The following code is written in the file
single_write.c:
The first two lines include standard C headers. The following four
lines include C headers specific to OCaml installed by the
distribution. The unixsupport.h header defines reusable C
functions of the OCaml Unix library.
The most important line is the call to write. Since the call may
block (if the descriptor is a pipe or a socket) we need to release the
global lock on the OCaml runtime immediately before the call
(line 20) and reacquire it right after
(line 22). This makes the function compatible with the
Thread module (see chapter 7): it allows
other threads to execute during the blocking call.
During the system call OCaml may perform a garbage collection and
the address of the OCaml string buf may move in memory. To
solve this problem we copy buf into the C string iobuf.
This has an additional cost, but only in the order of magnitude of
10% (and not 50% as one might think) because the overall cost of the
function is dominated by the system call. The size of this C string is
defined in unix_support.h. If an error occurs during the system
call (indicated by a negative return value) it is propagated to
OCaml by the function uerror, defined in the OCaml Unix library.
To access this code from OCaml, the file unix.mli declares:
But in practice we verify the arguments before calling the function:
This function has been available in the Unix module since version
3.08. But if we had written the program above ourselves we would
need to compile it as follows to use it (assuming the OCaml code is
in the files write.mli and write.ml):
It is often more practical to build a library write.cma containing
both the C and the OCaml code:
The library write.cma can then be used like unix.cma:
The semantics of single_write is as close as possible to the
system call write. The only remaining difference is when the
original string is very long (greater than UNIX_BUFFER_SIZE); the
call may then not write all the data and must be iterated. The
atomicity of write (guaranteed for regular files) is thus not
guaranteed for long writes. This difference is generally insignificant but one should
be aware of it.
On top of this function we can implement a higher-level function
really_write, analogous to the function really_read of the
multiplexer example, that writes exactly the requested amount of data
(but not atomically).